Publications
in reversed chronological order, generated by jekyll-scholar.
2026
- [J6]
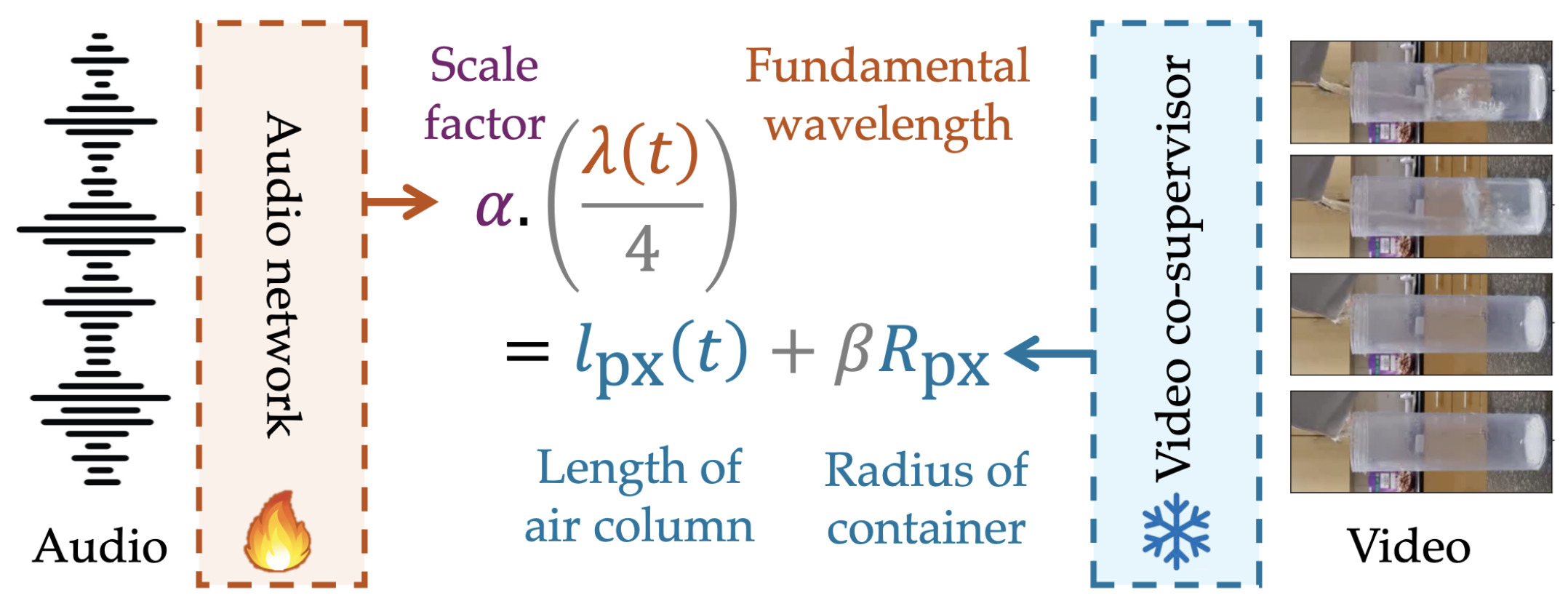 The Sound of Water: Inferring Physical Properties from Pouring LiquidsIEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2026New! Coming soonNote: Extended version of the ICASSP paper
The Sound of Water: Inferring Physical Properties from Pouring LiquidsIEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2026New! Coming soonNote: Extended version of the ICASSP paper@article{bagad2026pouringpami, project = {https://bpiyush.github.io/pouring-water-website/}, author = {Bagad, Piyush and Tapaswi, Makarand and Snoek, Cees G M and Zisserman, Andrew}, title = {{The Sound of Water: Inferring Physical Properties from Pouring Liquids}}, year = {2026}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI)} } - [P3]
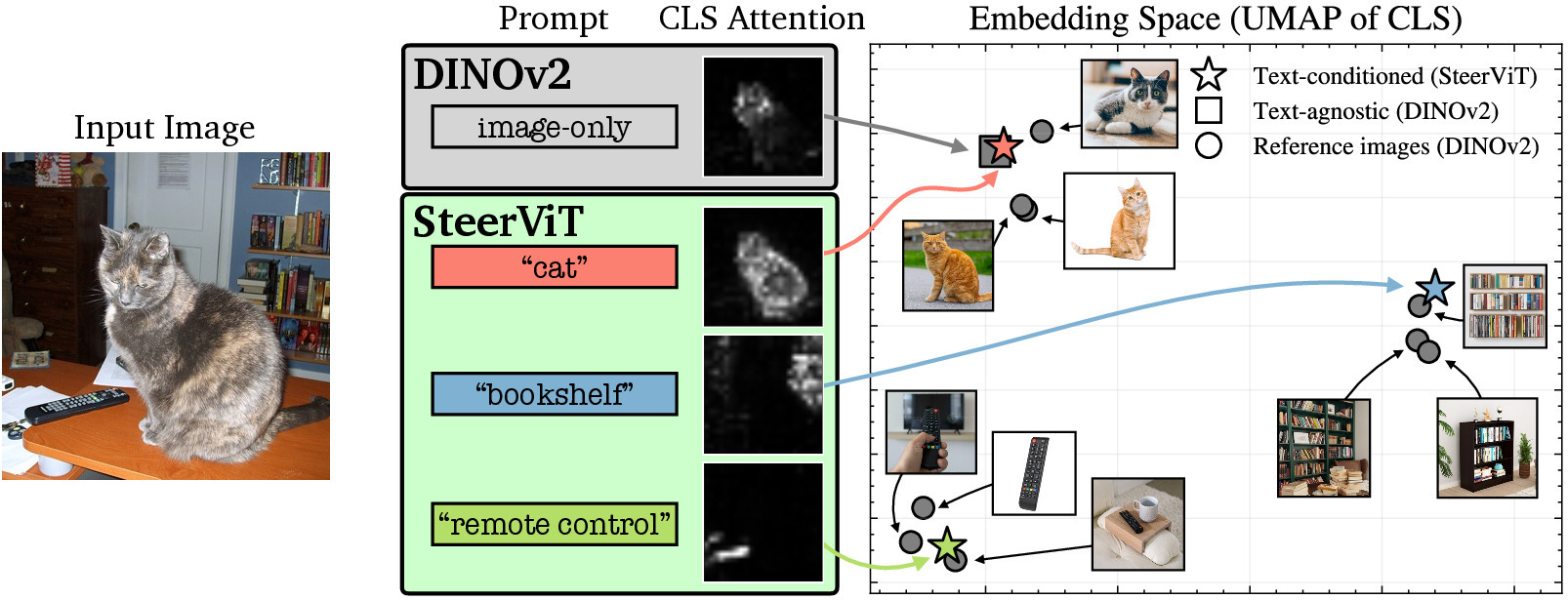 Steerable Vision TransformersarXiv:2604.02327, Apr 2026New!Note: Also at CVPRW26: CV-in-the-Wild
Steerable Vision TransformersarXiv:2604.02327, Apr 2026New!Note: Also at CVPRW26: CV-in-the-WildPretrained Vision Transformers (ViTs) such as DINOv2 and MAE provide generic image features that can be applied to a variety of downstream tasks such as retrieval, classification, and segmentation. However, such representations tend to focus on the most salient visual cues in the image, with no way to direct them toward less prominent concepts of interest. In contrast, Multimodal LLMs can be guided with textual prompts, but the resulting representations tend to be language-centric and lose their effectiveness for generic visual tasks. To address this, we introduce Steerable Visual Representations, a new class of visual representations, whose global and local features can be steered with natural language. While most vision-language models (e.g., CLIP) fuse text with visual features after encoding (late fusion), we inject text directly into the layers of the visual encoder (early fusion) via lightweight cross-attention. We introduce benchmarks for measuring representational steerability, and demonstrate that our steerable visual features can focus on any desired objects in an image while preserving the underlying representation quality. Our method also matches or outperforms dedicated approaches on anomaly detection and personalized object discrimination, exhibiting zero-shot generalization to out-of-distribution tasks.
@article{ruthardt2026steervit, author = {Ruthardt, Jona and Gaur, Manu and Ramanan, Deva and Tapaswi, Makarand and Asano, Yuki M}, title = {{Steerable Vision Transformers}}, year = {2026}, month = apr, journal = {arXiv:2604.02327} } - [C49]
 One Identity, Many Roles: Multimodal Entity Coreference for Enhanced Video Situation RecognitionBalaji Darur, Amanmeet Garg, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition, Findings Track (CVPRF), Jun 2026New!Note: Also at CVPRW26: VidLLMs
One Identity, Many Roles: Multimodal Entity Coreference for Enhanced Video Situation RecognitionBalaji Darur, Amanmeet Garg, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition, Findings Track (CVPRF), Jun 2026New!Note: Also at CVPRW26: VidLLMsVideos tell stories through evolving interactions between entities, yet models still struggle to capture "who did what to whom, with what, how, and where" across time. Video Situation Recognition (VidSitu) addresses this through a structured prediction task over actions and event role pairs with descriptive captions. On the other hand, the recurrence of entities in different roles or appearances shapes the narrative itself, making their consistent identification crucial for coherent understanding. Linking the VidSitu task to entity continuity reveals a natural synergy between visual grounding and captioning, where visual clusters and captions describe the same entity and complement each other. To this end, we introduce CineMEC, a multi-stage approach that addresses Multimodal Entity Coreference (MEC) for VidSitu by unifying event role mention groups with visual clusters of entities. Evaluations on the extended VidSitu dataset demonstrate significant improvements in captioning and entity-level coreference metrics as well as the model’s ability to ground entities consistently throughout video, all without explicit grounding supervision during training.
@inproceedings{balaji2026cinemec, author = {Darur, Balaji and Garg, Amanmeet and Tapaswi, Makarand}, title = {{One Identity, Many Roles: Multimodal Entity Coreference for Enhanced Video Situation Recognition}}, year = {2026}, booktitle = {Conference on Computer Vision and Pattern Recognition, Findings Track (CVPRF)}, month = jun } - [W14]
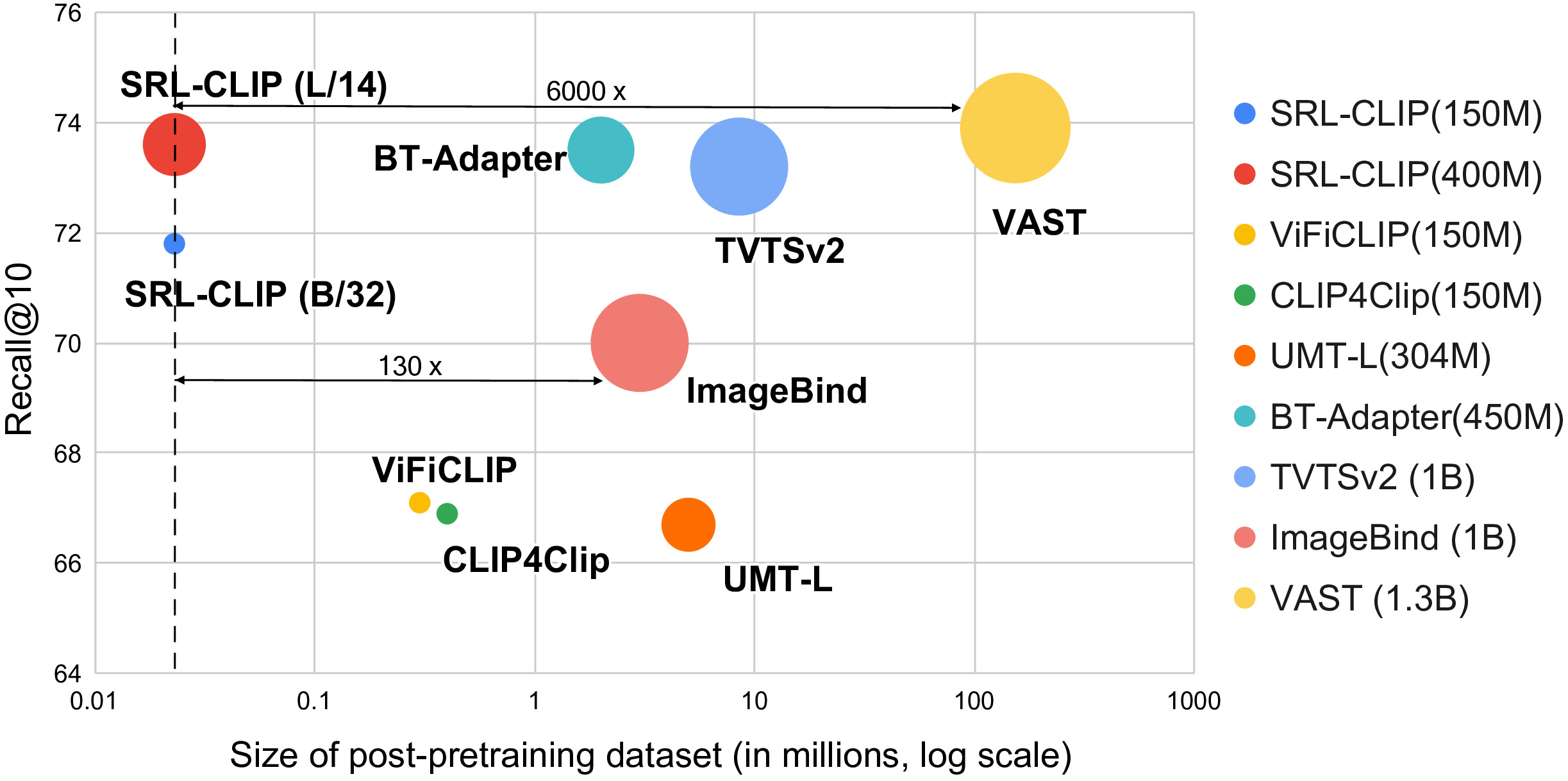 SRL-CLIP: Efficient CLIP Video Adaptation via Structured Semantic Role LabelsDarshan Singh, Zeeshan Khan, and Makarand TapaswiIn CVPR Workshop on CV with Small Data (CV4Smalls), Jun 2026New! 🏅 Best Paper Award Candidate
SRL-CLIP: Efficient CLIP Video Adaptation via Structured Semantic Role LabelsDarshan Singh, Zeeshan Khan, and Makarand TapaswiIn CVPR Workshop on CV with Small Data (CV4Smalls), Jun 2026New! 🏅 Best Paper Award CandidateAdapting CLIP for videos has gained popularity due to its semantic and rich representation. While CLIP is a good starting point, it typically undergoes post-pretraining (contrastive finetuning) on large video narration or caption datasets (e.g., HowTo100M, WebVid2.5M). However, such narrations or captions often lack comprehensive information needed to represent a video holistically. As the learning signal from text is sparse, the visual learning is inefficient and adaptation requires millions of samples to post-pretrain. In this work, we ask: is it possible to efficiently adapt CLIP for general and holistic video understanding? We use videos labeled with structured and dense Semantic Role Labels (SRLs) that capture actions, people or objects, their attributes, adverbs (manner), and location in a structured format representing the entire video in a holistic way. We generate rule-based captions from SRLs and demonstrate that simple contrastive finetuning on a mere 23k video-caption pairs is adequate to learn powerful, transferable representations applicable across a diverse range of video understanding tasks that require varying levels of perceptual granularity. Our adapted CLIP model, SRL-CLIP, exhibits comparable or superior performance on zero-shot text-to-video retrieval compared to state-of-the-art models that possess 4-8x more parameters and are post-pretrained on up to 6000x more data. SRL-CLIP surpasses CLIP on multiple video benchmarks, underscoring the efficient learning and improved representations.
@inproceedings{singh2026srlclip, author = {Singh, Darshan and Khan, Zeeshan and Tapaswi, Makarand}, title = {{SRL-CLIP: Efficient CLIP Video Adaptation via Structured Semantic Role Labels}}, year = {2026}, booktitle = {CVPR Workshop on CV with Small Data (CV4Smalls)}, month = jun, doi = {} } - [C48]
 STRinGS: Selective Text Refinement in Gaussian SplattingIn Winter Conference on Applications of Computer Vision (WACV), Mar 2026
STRinGS: Selective Text Refinement in Gaussian SplattingIn Winter Conference on Applications of Computer Vision (WACV), Mar 2026Text as signs, labels, or instructions is a critical element of real-world scenes as they can convey important contextual information. 3D representations such as 3D Gaussian Splatting (3DGS) struggle to preserve fine-grained text details, while achieving high visual fidelity. Small errors in textual element reconstruction can lead to significant semantic loss. We propose STRinGS, a text-aware, selective refinement framework to address this issue for 3DGS reconstruction. Our method treats text and non-text regions separately, refining text regions first and merging them with non-text regions later for full-scene optimization. STRinGS produces sharp, readable text even in challenging configurations. We introduce a text readability measure OCR Character Error Rate (CER) to evaluate the efficacy on text regions. STRinGS results in a 63.6% relative improvement over 3DGS at just 7K iterations. We also introduce a curated dataset STRinGS-360 with diverse text scenarios to evaluate text readability in 3D reconstruction. Our method and dataset together push the boundaries of 3D scene understanding in text-rich environments, paving the way for more robust text-aware reconstruction methods.
@inproceedings{raundhal2026strings, author = {Raundhal, Abhinav and Behera, Gaurav and Narayanan, P J and Sarvadevabhatla, Ravi Kiran and Tapaswi, Makarand}, title = {{STRinGS: Selective Text Refinement in Gaussian Splatting}}, year = {2026}, booktitle = {Winter Conference on Applications of Computer Vision (WACV)}, month = mar }





2025
- [J5]
 MALeR: Improving Compositional Fidelity in Layout-Guided GenerationShivank Saxena, Dhruv Srivastava, and Makarand TapaswiACM Transactions on Graphics (ToG), Dec 2025Presented at Siggraph Asia (journal track)
MALeR: Improving Compositional Fidelity in Layout-Guided GenerationShivank Saxena, Dhruv Srivastava, and Makarand TapaswiACM Transactions on Graphics (ToG), Dec 2025Presented at Siggraph Asia (journal track)Recent advances in text-to-image models have enabled a new era of creative and controllable image generation. However, generating compositional scenes with multiple subjects and attributes remains a significant challenge. To enhance user control over subject placement, several layout-guided methods have been proposed. However, these methods face numerous challenges, particularly in compositional scenes. Unintended subjects often appear outside the layouts, generated images can be out-of-distribution and contain unnatural artifacts, or attributes bleed across subjects, leading to incorrect visual outputs. In this work, we propose MALeR, a method that addresses each of these challenges. Given a text prompt and corresponding layouts, our method prevents subjects from appearing outside the given layouts while being in-distribution. Additionally, we propose a masked, attribute-aware binding mechanism that prevents attribute leakage, enabling accurate rendering of subjects with multiple attributes, even in complex compositional scenes. Qualitative and quantitative evaluation demonstrates that our method achieves superior performance in compositional accuracy, generation consistency, and attribute binding compared to previous work. MALeR is particularly adept at generating images of scenes with multiple subjects and multiple attributes per subject.
@article{saxena2025maler, author = {Saxena, Shivank and Srivastava, Dhruv and Tapaswi, Makarand}, title = {{MALeR: Improving Compositional Fidelity in Layout-Guided Generation}}, year = {2025}, journal = {ACM Transactions on Graphics (ToG)}, volume = {44}, number = {6}, month = dec, doi = {10.1145/3763341} } - [C47]
 What You See is What You Ask: Evaluating Audio DescriptionsDivy Kala, Eshika Khandelwal, and Makarand TapaswiIn Empirical Methods in Natural Language Processing (EMNLP), Nov 2025Note: Main conference track, long paper
What You See is What You Ask: Evaluating Audio DescriptionsDivy Kala, Eshika Khandelwal, and Makarand TapaswiIn Empirical Methods in Natural Language Processing (EMNLP), Nov 2025Note: Main conference track, long paperAudio descriptions (ADs) narrate important visual details in movies, enabling Blind and Low Vision (BLV) users to understand narratives and appreciate visual details. Existing works in automatic AD generation mostly focus on few-second trimmed clips, and evaluate them by comparing against a single ground-truth reference AD. However, writing ADs is inherently subjective. Through alignment and analysis of two independent AD tracks for the same movies, we quantify the subjectivity in when and whether to describe, and what and how to highlight. Thus, we show that working with trimmed clips is inadequate. We propose ADQA, a QA benchmark that evaluates ADs at the level of few-minute long, coherent video segments, testing whether they would help BLV users understand the story and appreciate visual details. ADQA features visual appreciation (VA) questions about visual facts and narrative understanding (NU) questions based on the plot. Through ADQA, we show that current AD generation methods lag far behind human-authored ADs. We conclude with several recommendations for future work and introduce a public leaderboard for benchmarking.
@inproceedings{kala2025adqa, author = {Kala, Divy and Khandelwal, Eshika and Tapaswi, Makarand}, title = {{What You See is What You Ask: Evaluating Audio Descriptions}}, year = {2025}, booktitle = {Empirical Methods in Natural Language Processing (EMNLP)}, month = nov, doi = {10.18653/v1/2025.emnlp-main.1199} } - [P2]
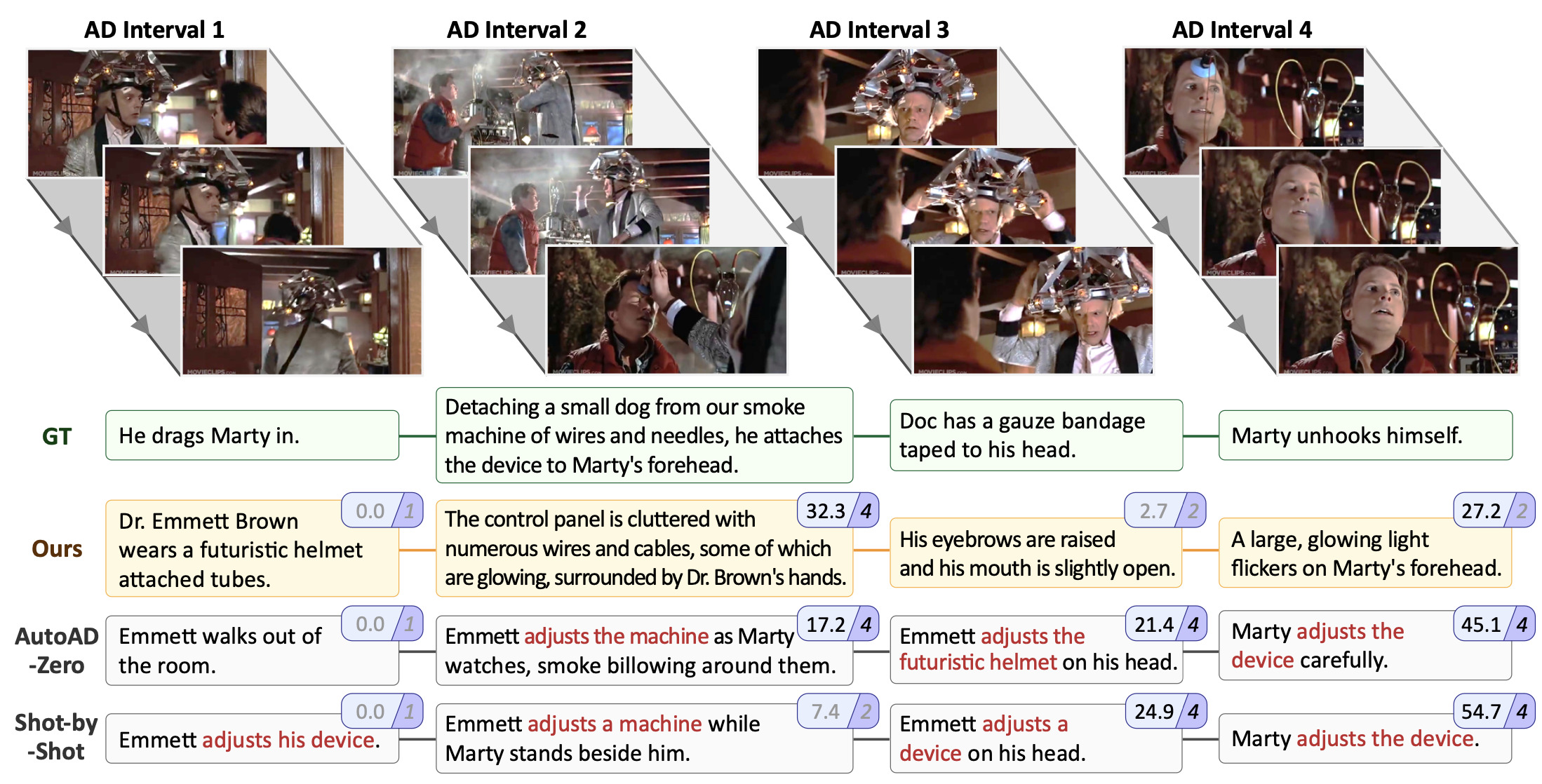 More than a Moment: Towards Coherent Sequences of Audio DescriptionsEshika Khandelwal, Junyu Xie, Tengda Han, Max Bain, Arsha Nagrani, Andrew Zisserman, Gül Varol, and Makarand TapaswiarXiv:2510.25440, Oct 2025
More than a Moment: Towards Coherent Sequences of Audio DescriptionsEshika Khandelwal, Junyu Xie, Tengda Han, Max Bain, Arsha Nagrani, Andrew Zisserman, Gül Varol, and Makarand TapaswiarXiv:2510.25440, Oct 2025Audio Descriptions (ADs) convey essential on-screen information, allowing visually impaired audiences to follow videos. To be effective, ADs must form a coherent sequence that helps listeners to visualise the unfolding scene, rather than describing isolated moments. However, most automatic methods generate each AD independently, often resulting in repetitive, incoherent descriptions. To address this, we propose a training-free method, CoherentAD, that first generates multiple candidate descriptions for each AD time interval, and then performs auto-regressive selection across the sequence to form a coherent and informative narrative. To evaluate AD sequences holistically, we introduce a sequence-level metric, StoryRecall, which measures how well the predicted ADs convey the ground truth narrative, alongside repetition metrics that capture the redundancy across consecutive AD outputs. Our method produces coherent AD sequences with enhanced narrative understanding, outperforming prior approaches that rely on independent generations.
@article{khandelwal2025coherentad, author = {Khandelwal, Eshika and Xie, Junyu and Han, Tengda and Bain, Max and Nagrani, Arsha and Zisserman, Andrew and Varol, Gül and Tapaswi, Makarand}, title = {{More than a Moment: Towards Coherent Sequences of Audio Descriptions}}, year = {2025}, month = oct, journal = {arXiv:2510.25440} } - [C46]
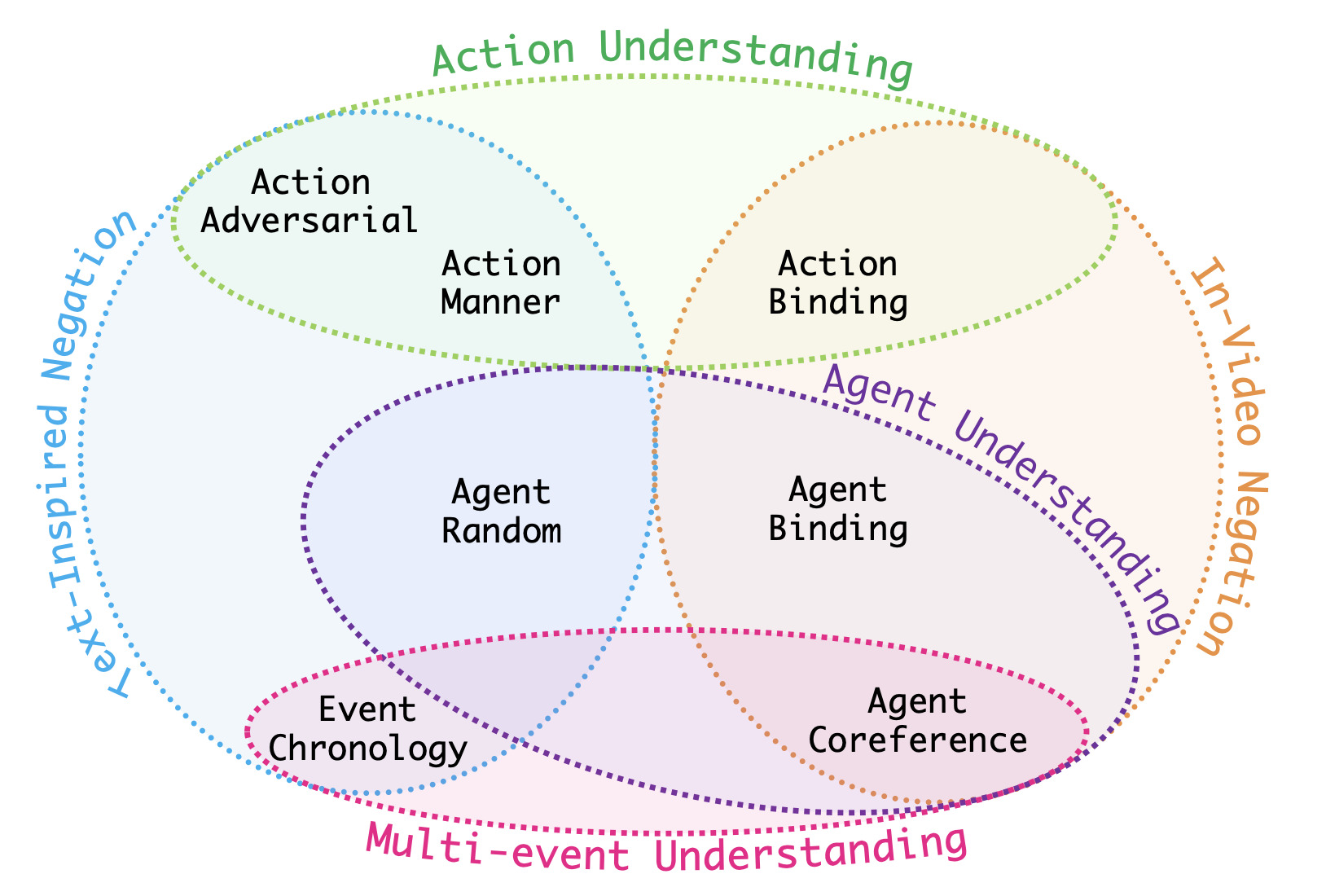 VELOCITI: Benchmarking Video-Language Compositional Reasoning with Strict EntailmentDarshana Saravanan* , Varun Gupta* , Darshan Singh*, Zeeshan Khan, Vineet Gandhi, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2025Note: Also at CVPR Workshops: VidLLMs, EVAL-FoMo, WiCV, MMFM
VELOCITI: Benchmarking Video-Language Compositional Reasoning with Strict EntailmentDarshana Saravanan* , Varun Gupta* , Darshan Singh*, Zeeshan Khan, Vineet Gandhi, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2025Note: Also at CVPR Workshops: VidLLMs, EVAL-FoMo, WiCV, MMFMA fundamental aspect of compositional reasoning in a video is associating people and their actions across time. Recent years have seen great progress in general-purpose vision or video models and a move towards long-video understanding. While exciting, we take a step back and ask: are current models good at compositional reasoning on short videos? To this end, we introduce VELOCITI, a benchmark to study Video-LLMs by disentangling and assessing the comprehension of agents, actions, and their associations across multiple events. We adopt the Video-Language Entailment setup and propose StrictVLE that requires correct classification (rather than ranking) of the positive and negative caption. We evaluate several models and observe that even the best, LLaVA-OneVision (44.5%) and Gemini-1.5-Pro (49.3%), are far from human accuracy at 93.0%. Results show that action understanding lags behind agents, and negative captions created using entities appearing in the video perform worse than those obtained from pure text manipulation. We also present challenges with ClassicVLE and multiple-choice (MC) evaluation, strengthening our preference for StrictVLE. Finally, we validate that our benchmark requires visual inputs of multiple frames making it ideal to study video-language compositional reasoning.
@inproceedings{ddv2025velociti, author = {Saravanan, Darshana and Gupta, Varun and Singh, Darshan and Khan, Zeeshan and Gandhi, Vineet and Tapaswi, Makarand}, title = {{VELOCITI: Benchmarking Video-Language Compositional Reasoning with Strict Entailment}}, year = {2025}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR52734.2025.01762} } - [W13]
 Investigating Mechanisms for In-Context Vision Language BindingDarshana Saravanan, Makarand Tapaswi, and Vineet GandhiIn CVPR Workshop on Mechanistic Interpretability in Vision (MIV), Jun 2025
Investigating Mechanisms for In-Context Vision Language BindingDarshana Saravanan, Makarand Tapaswi, and Vineet GandhiIn CVPR Workshop on Mechanistic Interpretability in Vision (MIV), Jun 2025To understand a prompt, Vision-Language models (VLMs) must perceive the image, comprehend the text, and build associations within and across both modalities. For instance, given an ’image of a red toy car’, the model should associate this image to phrases like ’car’, ’red toy’, ’red object’, etc. Feng and Steinhardt propose the Binding ID mechanism in LLMs, suggesting that the entity and its corresponding attribute tokens share a Binding ID vector in the model activations. We investigate this for image-text binding in VLMs using a synthetic dataset and task that requires models to associate 3D objects in an image with their descriptions in the text. Our experiments demonstrate that VLMs assign a distinct Binding ID to an object’s image tokens and its textual references, enabling in-context association.
@inproceedings{saravanan2025bindingid, author = {Saravanan, Darshana and Tapaswi, Makarand and Gandhi, Vineet}, title = {{Investigating Mechanisms for In-Context Vision Language Binding}}, year = {2025}, booktitle = {CVPR Workshop on Mechanistic Interpretability in Vision (MIV)}, month = jun, doi = {10.1109/CVPRW67362.2025.00476} } - [C45]
 IdentifyMe: A Challenging Mention Resolution Benchmark for LLMsIn Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), May 2025Note: Main conference, Short paper
IdentifyMe: A Challenging Mention Resolution Benchmark for LLMsIn Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), May 2025Note: Main conference, Short paperRecent evaluations of LLMs on coreference resolution have revealed that traditional output formats and evaluation metrics do not fully capture the models’ referential understanding. To address this, we introduce IdentifyMe, a new benchmark for mention resolution presented in a multiple-choice question (MCQ) format, commonly used for evaluating LLMs. IdentifyMe features long narratives and employs heuristics to exclude easily identifiable mentions, creating a more challenging task. The benchmark also consists of a curated mixture of different mention types and corresponding entities, allowing for a fine-grained analysis of model performance. We evaluate both closed- and open source LLMs on IdentifyMe and observe a significant performance gap (20-30%) between the state-of-the-art sub-10B open models vs. closed ones. We observe that pronominal mentions, which have limited surface information, are typically much harder for models to resolve than nominal mentions. Additionally, we find that LLMs often confuse entities when their mentions overlap in nested structures. The highest-scoring model, GPT-4o, achieves 81.9% accuracy, highlighting the strong referential capabilities of state-of-the-art LLMs while also indicating room for further improvement.
@inproceedings{manikantan2025identifyme, author = {Manikantan, Kawshik and Tapaswi, Makarand and Gandhi, Vineet and Toshniwal, Shubham}, title = {{IdentifyMe: A Challenging Mention Resolution Benchmark for LLMs}}, year = {2025}, booktitle = {Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL)}, month = may, doi = {10.18653/v1/2025.naacl-short.64} } - [C44] The Sound of Water: Inferring Physical Properties from Pouring LiquidsIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Apr 2025Note: Long version on arXiv, accepted to T-PAMI
We study the connection between audio-visual observations and the underlying physics of a mundane yet intriguing everyday activity: pouring liquids. Given only the sound of liquid pouring into a container, our objective is to automatically infer physical properties such as the liquid level, the shape and size of the container, the pouring rate and the time to fill. To this end, we: (i) show in theory that these properties can be determined from the fundamental frequency (pitch); (ii) train a pitch detection model with supervision from simulated data and visual data with a physics-inspired objective; (iii) introduce a new large dataset of real pouring videos for a systematic study; (iv) show that the trained model can indeed infer these physical properties for real data; and finally, (v) we demonstrate strong generalization to various container shapes, other datasets, and in-the-wild YouTube videos. Our work presents a keen understanding of a narrow yet rich problem at the intersection of acoustics, physics, and learning. It opens up applications to enhance multisensory perception in robotic pouring.
@inproceedings{bagad2025pouring, author = {Bagad, Piyush and Tapaswi, Makarand and Snoek, Cees G M and Zisserman, Andrew}, title = {{The Sound of Water: Inferring Physical Properties from Pouring Liquids}}, year = {2025}, booktitle = {International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, month = apr, doi = {10.1109/ICASSP49660.2025.10889950} } - [C43]
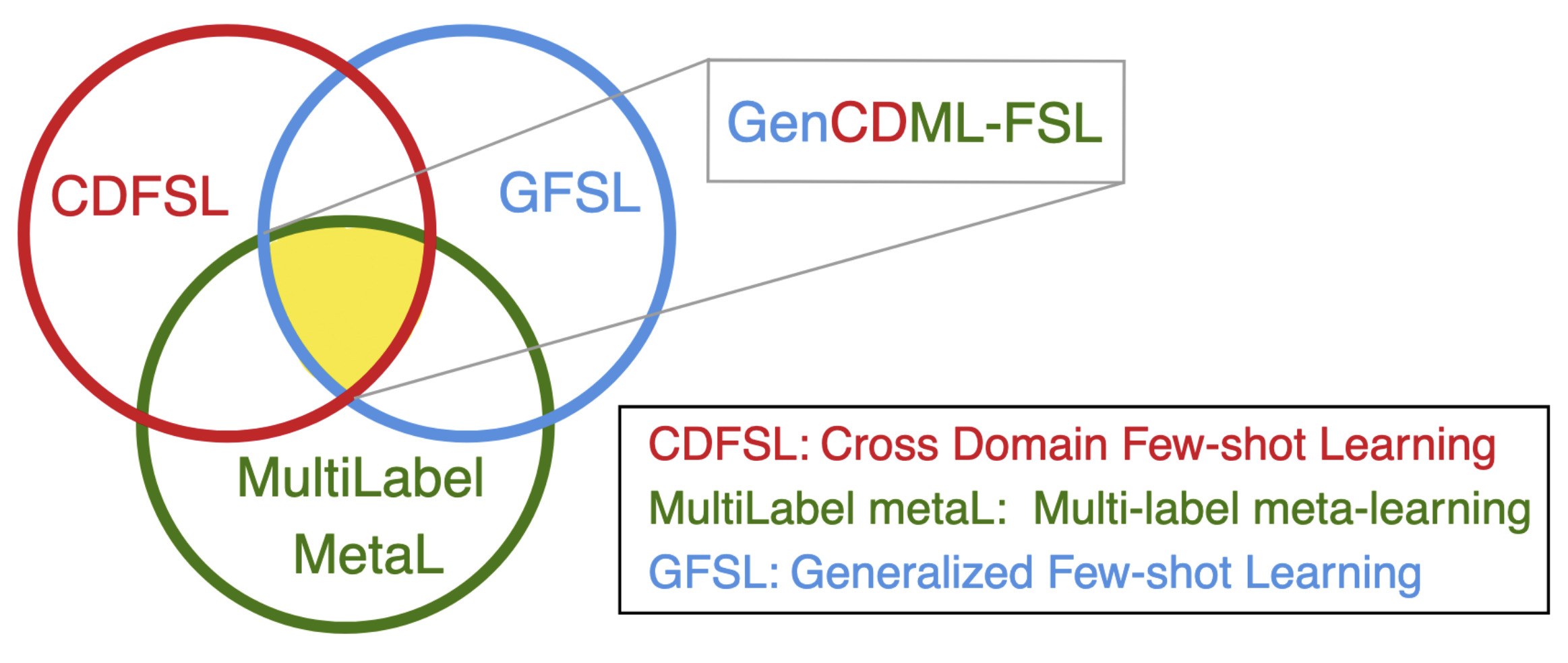 Generalized Cross-domain Multi-label Few-shot Learning for Chest X-raysIn International Symposium on Biomedical Imaging (ISBI), Apr 2025Note: Long version on arXiv
Generalized Cross-domain Multi-label Few-shot Learning for Chest X-raysIn International Symposium on Biomedical Imaging (ISBI), Apr 2025Note: Long version on arXivReal-world application of chest X-ray abnormality classification requires dealing with several challenges: (i) limited training data; (ii) training and evaluation sets that are derived from different domains; and (iii) classes that appear during training may have partial overlap with classes of interest during evaluation. To address these challenges, we present an integrated framework called Generalized Cross-Domain Multi-Label Few-Shot Learning (GenCDML-FSL). The framework supports overlap in classes during training and evaluation, cross-domain transfer, adopts meta-learning to learn using few training samples, and assumes each chest X-ray image is either normal or associated with one or more abnormalities. Furthermore, we propose Generalized Episodic Training (GenET), a training strategy that equips models to operate with multiple challenges observed in the GenCDML-FSL scenario. Comparisons with well-established methods such as transfer learning, hybrid transfer learning, and multi-label meta-learning on multiple datasets show the superiority of our approach.
@inproceedings{aimen2025gencdmlfsl, author = {Aimen, Aroof and Verma, Arsh and Tapaswi, Makarand and Krishnan, Narayanan C}, title = {{Generalized Cross-domain Multi-label Few-shot Learning for Chest X-rays}}, year = {2025}, booktitle = {International Symposium on Biomedical Imaging (ISBI)}, month = apr, doi = {10.1109/ISBI60581.2025.10980999} } - [C42]
 Seeing Eye to AI: Comparing Human Gaze and Model Attention in Video MemorabilityIn Winter Conference on Applications of Computer Vision (WACV), Feb 2025
Seeing Eye to AI: Comparing Human Gaze and Model Attention in Video MemorabilityIn Winter Conference on Applications of Computer Vision (WACV), Feb 2025Understanding what makes a video memorable has important applications in advertising or education technology. Towards this goal, we investigate spatio-temporal attention mechanisms underlying video memorability. Different from previous works that fuse multiple features, we adopt a simple CNN+Transformer architecture that enables analysis of spatio-temporal attention while matching state-of-the-art (SoTA) performance on video memorability prediction. We compare model attention against human gaze fixations collected through a small-scale eye-tracking study where humans perform the video memory task. We uncover the following insights: (i) Quantitative saliency metrics show that our model, trained only to predict a memorability score, exhibits similar spatial attention patterns to human gaze, especially for more memorable videos. (ii) Both, the model and humans, assign greater importance to initial frames in a video. (iii) Panoptic segmentation reveals that both (model and humans) assign a greater share of attention to things and less attention to stuff as compared to their occurrence probability. Thus, our approach captures key spatio-temporal and semantic attention signatures that are relevant for memorability.
@inproceedings{kumar2025videomem, author = {Kumar, Prajneya and Khandelwal, Eshika and Tapaswi, Makarand and Sreekumar, Vishnu}, title = {{Seeing Eye to AI: Comparing Human Gaze and Model Attention in Video Memorability}}, year = {2025}, booktitle = {Winter Conference on Applications of Computer Vision (WACV)}, month = feb, doi = {10.1109/WACV61041.2025.00209} } - [J4]
 No Detail Left Behind: Revisiting Self-Retrieval for Fine-Grained Image CaptioningManu Gaur , Darshan Singh, and Makarand TapaswiTransactions on Machine Learning Research (TMLR), Jan 2025🗞️ Journal-to-Conference certification | Presented at NeurIPS 2026
No Detail Left Behind: Revisiting Self-Retrieval for Fine-Grained Image CaptioningManu Gaur , Darshan Singh, and Makarand TapaswiTransactions on Machine Learning Research (TMLR), Jan 2025🗞️ Journal-to-Conference certification | Presented at NeurIPS 2026Image captioning systems are unable to generate fine-grained captions as they are trained on data that is either noisy (alt-text) or generic (human annotations). This is further exacerbated by maximum likelihood training that encourages generation of frequently occurring phrases. Previous works have tried to address this limitation by fine-tuning captioners with a self-retrieval (SR) reward. However, we find that SR fine-tuning has a tendency to reduce caption faithfulness and even hallucinate. In this work, we circumvent this bottleneck by improving the MLE initialization of the captioning system and designing a curriculum for the SR fine-tuning process. To this extent, we present (1) Visual Caption Boosting, a novel framework to instill fine-grainedness in generic image captioning datasets while remaining anchored in human annotations; and (2) BagCurri, a carefully designed training curriculum that more optimally leverages the contrastive nature of the self-retrieval reward. Jointly, they enable the captioner to describe fine-grained aspects in the image while preserving faithfulness to ground-truth captions. Our approach outperforms previous work by +8.9% on SR against 99 random distractors (RD100) (Dessi et al., 2023); and +7.6% on ImageCoDe. Additionally, existing metrics to evaluate captioning systems fail to reward diversity or evaluate a model’s fine-grained understanding ability. Our third contribution addresses this by proposing self-retrieval from the lens of evaluation. We introduce TrueMatch, a benchmark comprising bags of highly similar images that uses SR to assess the captioner’s ability to capture subtle visual distinctions. We evaluate and compare several state-of-the-art open-source MLLMs on TrueMatch, and find that our SR approach outperforms them all by a significant margin (e.g. +4.8% - 7.1% over Cambrian) while having 1-2 orders of magnitude fewer parameters.
@article{gaur2025selfretrieval, author = {Gaur, Manu and Singh, Darshan and Tapaswi, Makarand}, title = {{No Detail Left Behind: Revisiting Self-Retrieval for Fine-Grained Image Captioning}}, year = {2025}, journal = {Transactions on Machine Learning Research (TMLR)}, month = jan }









2024
- [C41]
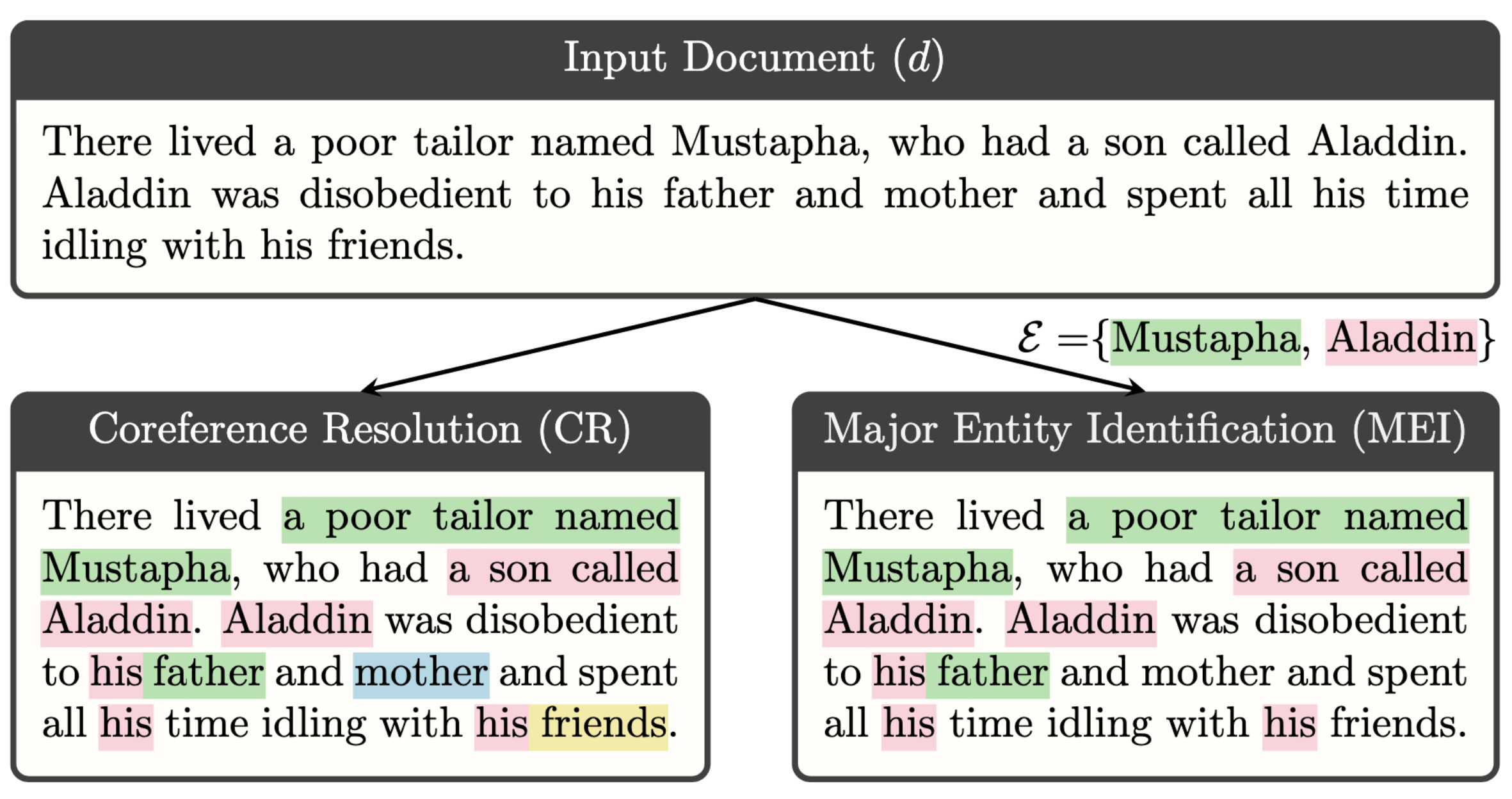 Major Entity Identification: A Generalizable Alternative to Coreference ResolutionIn Empirical Methods in Natural Language Processing (EMNLP), Nov 2024Note: Main conference
Major Entity Identification: A Generalizable Alternative to Coreference ResolutionIn Empirical Methods in Natural Language Processing (EMNLP), Nov 2024Note: Main conferenceThe limited generalization of coreference resolution (CR) models has been a major bottleneck in the task’s broad application. Prior work has identified annotation differences, especially for mention detection, as one of the main reasons for the generalization gap and proposed using additional annotated target domain data. Rather than relying on this additional annotation, we propose an alternative formulation of the CR task, Major Entity Identification (MEI), where we: (a) assume the target entities to be specified in the input, and (b) limit the task to only the frequent entities. Through extensive experiments, we demonstrate that MEI models generalize well across domains on multiple datasets with supervised models and LLM-based few-shot prompting. Additionally, the MEI task fits the classification framework, which enables the use of classification-based metrics that are more robust than the current CR metrics. Finally, MEI is also of practical use as it allows a user to search for all mentions of a particular entity or a group of entities of interest.
@inproceedings{manikantan2024majorentityid, author = {Manikantan, Kawshik and Toshniwal, Shubham and Tapaswi, Makarand and Gandhi, Vineet}, title = {{Major Entity Identification: A Generalizable Alternative to Coreference Resolution}}, year = {2024}, booktitle = {Empirical Methods in Natural Language Processing (EMNLP)}, month = nov, doi = {10.18653/v1/2024.emnlp-main.652} } - [W12]
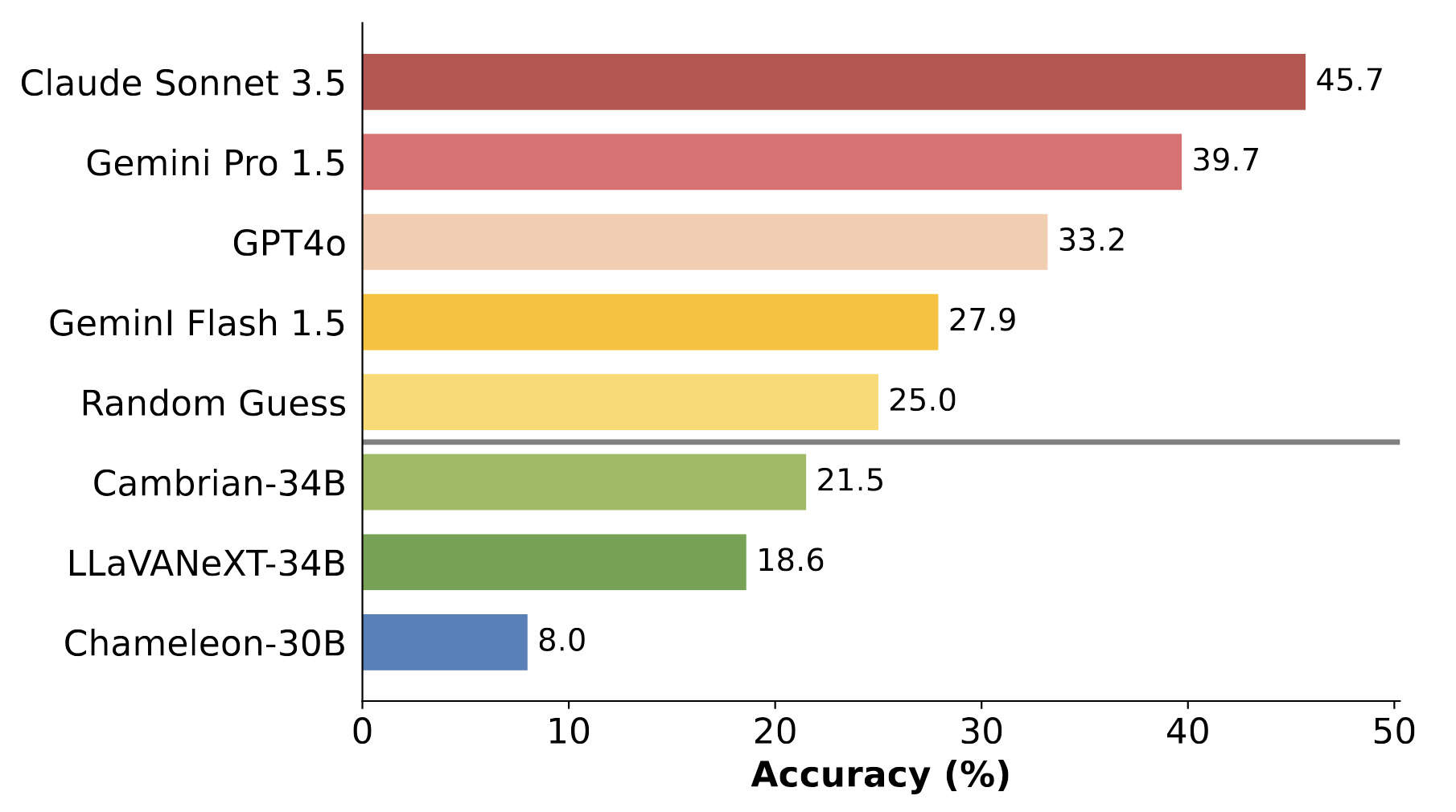 Detect, Describe, Discriminate: Moving Beyond VQA for MLLM EvaluationManu Gaur , Darshan Singh, and Makarand TapaswiIn ECCV Workshop on Emergent Visual Abilities and Limits of Foundation Models (EVAL-FoMo), Sep 2024
Detect, Describe, Discriminate: Moving Beyond VQA for MLLM EvaluationManu Gaur , Darshan Singh, and Makarand TapaswiIn ECCV Workshop on Emergent Visual Abilities and Limits of Foundation Models (EVAL-FoMo), Sep 2024Visual Question Answering (VQA) with multiple choice questions enables a vision-centric evaluation of Multimodal Large Language Models (MLLMs). Although it reliably checks the existence of specific visual abilities, it is easier for the model to select an answer from multiple choices (VQA evaluation) than to generate the answer itself. In this work, we offer a novel perspective: we evaluate how well an MLLM understands a specific visual concept by its ability to uniquely describe two extremely similar images that differ only in the targeted visual concept. Specifically, we assess the ability of MLLMs to capture specific points of visual differences using self-retrieval, i.e. by retrieving the target image using its generated caption against the other image in the pair serving as the distractor. We curate 247 highly similar image pairs as part of the D3 benchmark. For each image pair, the model is prompted to: (i) Detect a specific visual difference, and (ii) Describe the target image uniquely such that it (iii) Discriminates the target image from the distractor. Self-retrieval within D3 enables white-box evaluation across six different visual patterns, revealing that current models struggle to independently discern fine-grained visual differences, with open-source models failing to outperform random guess.
@inproceedings{gaur2024d3benchmark, author = {Gaur, Manu and Singh, Darshan and Tapaswi, Makarand}, title = {{Detect, Describe, Discriminate: Moving Beyond VQA for MLLM Evaluation}}, year = {2024}, booktitle = {ECCV Workshop on Emergent Visual Abilities and Limits of Foundation Models (EVAL-FoMo)}, month = sep } - [W11]
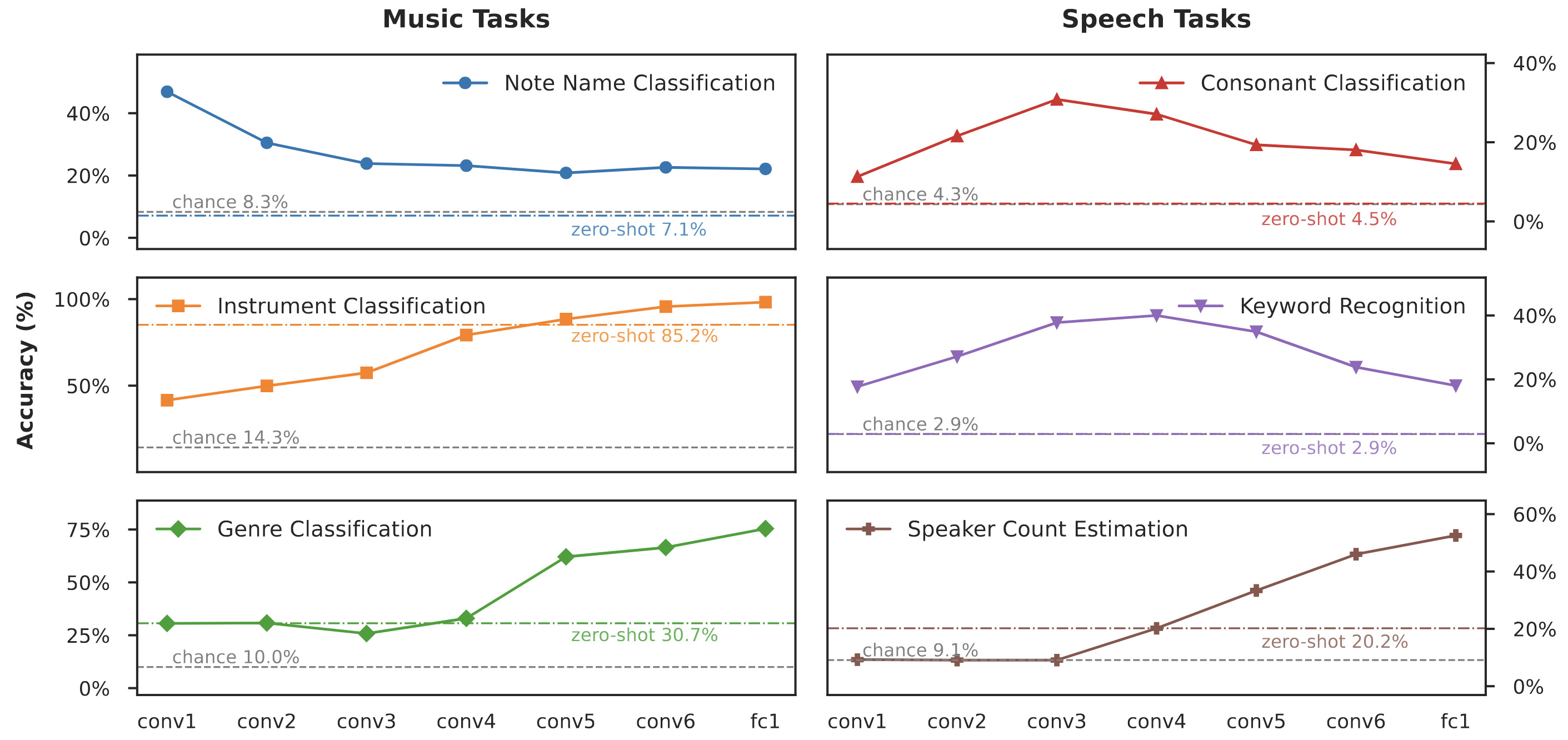 Localizing Auditory Concepts in CNNsPratyaksh Gautam, Makarand Tapaswi*, and Vinoo Alluri*In ICML Workshop on Mechanistic Interpretability (ICMLW-MI), Jul 2024
Localizing Auditory Concepts in CNNsPratyaksh Gautam, Makarand Tapaswi*, and Vinoo Alluri*In ICML Workshop on Mechanistic Interpretability (ICMLW-MI), Jul 2024Deep learning models are capable of complex auditory processing tasks such as keyword spotting, genre classification, and audio captioning, yet remain opaque. While several works have explored interpretability of neural networks for computer vision and natural language processing, the audio modality has been largely ignored. In this paper, we study the behavior of the audio CNN encoder used in the contrastively trained language-audio model, CLAP. In the domain of music and human speech sounds, we localize and identify the layers of the network that perform well on tasks of varying complexity, sometimes even outperforming the model’s final outputs. Digging deeper, we also localize specific dataset classes to neuron clusters within a layer and analyze a cluster’s contribution to the model’s discriminability for that class. To perform these analyses, we propose an automated framework that can leverage a small dataset of a few thousand samples to evaluate and score neuron clusters for their role in classification. Our findings provide insights into the hierarchical nature of representations in audio CNNs, paving the way for improved interpretability of audio model.
@inproceedings{gautam2024audioconcepts, author = {Gautam, Pratyaksh and Tapaswi, Makarand and Alluri, Vinoo}, title = {{Localizing Auditory Concepts in CNNs}}, year = {2024}, booktitle = {ICML Workshop on Mechanistic Interpretability (ICMLW-MI)}, month = jul } - [C40]
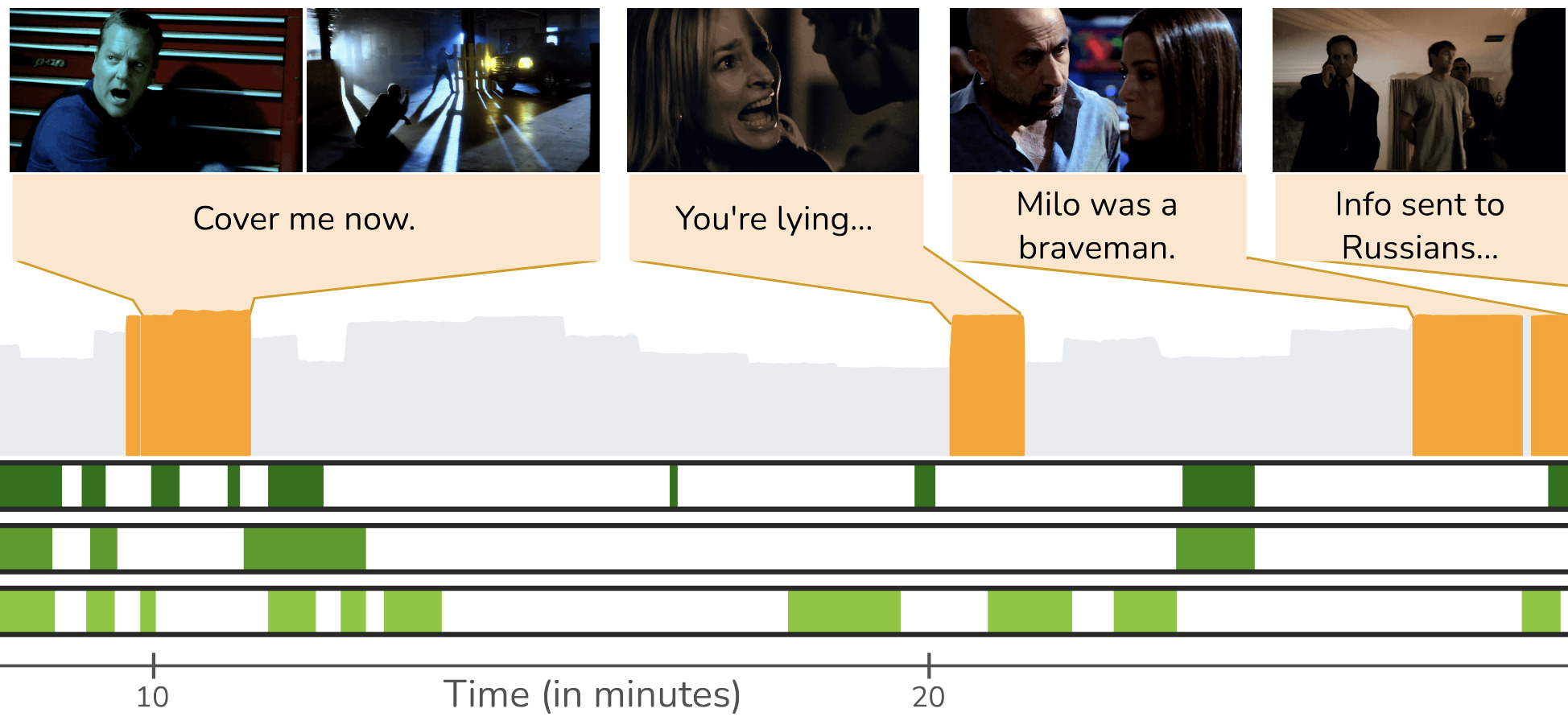 "Previously on ..." From Recaps to Story SummarizationAditya Kumar Singh, Dhruv Srivastava, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024
"Previously on ..." From Recaps to Story SummarizationAditya Kumar Singh, Dhruv Srivastava, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024We introduce multimodal story summarization by leveraging TV episode recaps - short video sequences interweaving key story moments from previous episodes to bring viewers up to speed. We propose PlotSnap, a dataset featuring two crime thriller TV shows with rich recaps and long episodes of 40 minutes. Story summarization labels are unlocked by matching recap shots to corresponding sub-stories in the episode. We propose a hierarchical model TaleSumm that processes entire episodes by creating compact shot and dialog representations, and predicts importance scores for each video shot and dialog utterance by enabling interactions between local story groups. Unlike traditional summarization, our method extracts multiple plot points from long videos. We present a thorough evaluation on story summarization, including promising cross-series generalization. TaleSumm also shows good results on classic video summarization benchmarks.
@inproceedings{singh2024recaps, author = {Singh, Aditya Kumar and Srivastava, Dhruv and Tapaswi, Makarand}, title = {{"Previously on ..." From Recaps to Story Summarization}}, year = {2024}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR52733.2024.01294} } - [C39]
 MICap: A Unified Model for Identity-aware Movie DescriptionsIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024
MICap: A Unified Model for Identity-aware Movie DescriptionsIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024Characters are an important aspect of any storyline and identifying and including them in descriptions is necessary for story understanding. While previous work has largely ignored identity and generated captions with someone (anonymized names), recent work formulates id-aware captioning as a fill-in-the-blanks (FITB) task, where, given a caption with blanks, the goal is to predict person id labels. However, to predict captions with ids, a two-stage approach is required: first predict captions with someone, then fill in identities. In this work, we present a new single stage approach that can seamlessly switch between id-aware caption generation or FITB when given a caption with blanks. Our model, Movie-Identity Captioner (MICap), uses a shared auto-regressive decoder that benefits from training with FITB and full-caption generation objectives, while the encoder can benefit from or disregard captions with blanks as input. Another challenge with id-aware captioning is the lack of a metric to capture subtle differences between person ids. To this end, we introduce iSPICE, a caption evaluation metric that focuses on identity tuples created through intermediate scene graphs. We evaluate MICap on Large-Scale Movie Description Challenge (LSMDC), where we show a 4.2% improvement in FITB accuracy, and a 1-2% bump in classic captioning metrics.
@inproceedings{haran2024micap, author = {Raajesh, Haran and Desanur, Naveen Reddy and Khan, Zeeshan and Tapaswi, Makarand}, title = {{MICap: A Unified Model for Identity-aware Movie Descriptions}}, year = {2024}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR52733.2024.01329} } - [W10]
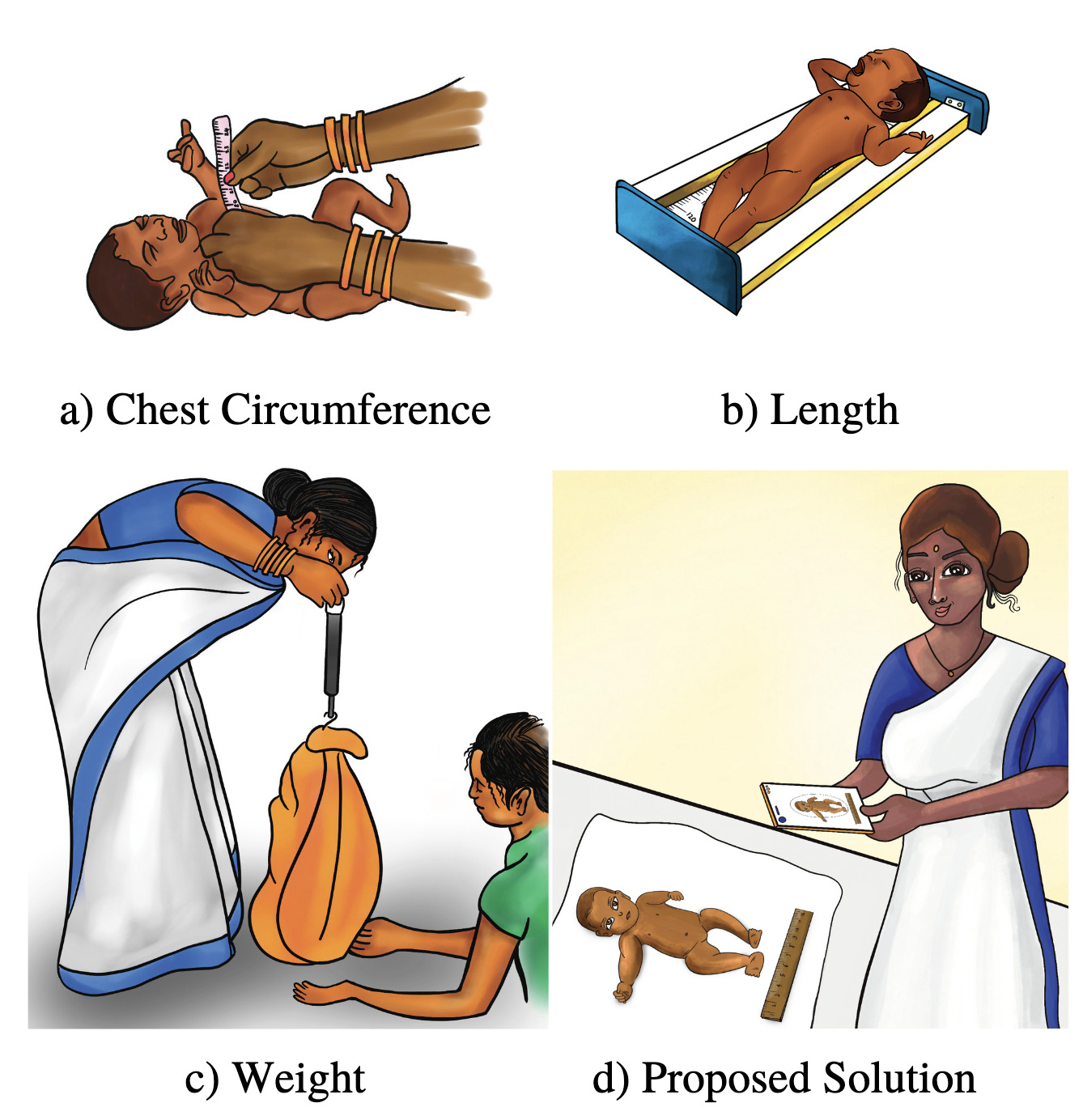 NurtureNet: A Multi-task Video-based Approach for Newborn AnthropometryYash Khandelwal, Mayur Arvind , Sriram Kumar , Ashish Gupta, Sachin Kumar Danisetty, Piyush Bagad, Anish Madan, Mayank Lunayach, Aditya Annavajjala, Abhishek Maiti, Sansiddh Jain, Aman Dalmia, Namrata Deka, Jerome White, Jigar Doshi, Angjoo Kanazawa, Rahul Panicker, Alpan Raval, Srinivas Rana, and Makarand TapaswiIn CVPR Worskhop on Computer Vision for Physiological Measurements (CVPM), Jun 2024🏆 Best Paper Award
NurtureNet: A Multi-task Video-based Approach for Newborn AnthropometryYash Khandelwal, Mayur Arvind , Sriram Kumar , Ashish Gupta, Sachin Kumar Danisetty, Piyush Bagad, Anish Madan, Mayank Lunayach, Aditya Annavajjala, Abhishek Maiti, Sansiddh Jain, Aman Dalmia, Namrata Deka, Jerome White, Jigar Doshi, Angjoo Kanazawa, Rahul Panicker, Alpan Raval, Srinivas Rana, and Makarand TapaswiIn CVPR Worskhop on Computer Vision for Physiological Measurements (CVPM), Jun 2024🏆 Best Paper AwardMalnutrition among newborns is a top public health concern in developing countries. Identification and subsequent growth monitoring are key to successful interventions. However, this is challenging in rural communities where health systems tend to be inaccessible and under-equipped, with poor adherence to protocol. Our goal is to equip health workers and public health systems with a solution for contactless newborn anthropometry in the community. We propose NurtureNet, a multi-task model that fuses visual information (a video taken with a low-cost smartphone) with tabular inputs to regress multiple anthropometry estimates including weight, length, head circumference, and chest circumference. We show that visual proxy tasks of segmentation and keypoint prediction further improve performance. We establish the efficacy of the model through several experiments and achieve a relative error of 3.9% and mean absolute error of 114.3 g for weight estimation. Model compression to 15 MB also allows offline deployment to low-cost smartphones.
@inproceedings{wiai2024nurturenet, author = {Khandelwal, Yash and Arvind, Mayur and Kumar, Sriram and Gupta, Ashish and Danisetty, Sachin Kumar and Bagad, Piyush and Madan, Anish and Lunayach, Mayank and Annavajjala, Aditya and Maiti, Abhishek and Jain, Sansiddh and Dalmia, Aman and Deka, Namrata and White, Jerome and Doshi, Jigar and Kanazawa, Angjoo and Panicker, Rahul and Raval, Alpan and Rana, Srinivas and Tapaswi, Makarand}, title = {{NurtureNet: A Multi-task Video-based Approach for Newborn Anthropometry}}, year = {2024}, booktitle = {CVPR Worskhop on Computer Vision for Physiological Measurements (CVPM)}, month = jun, doi = {10.1109/CVPRW63382.2024.00038} }






2023
- [C38]
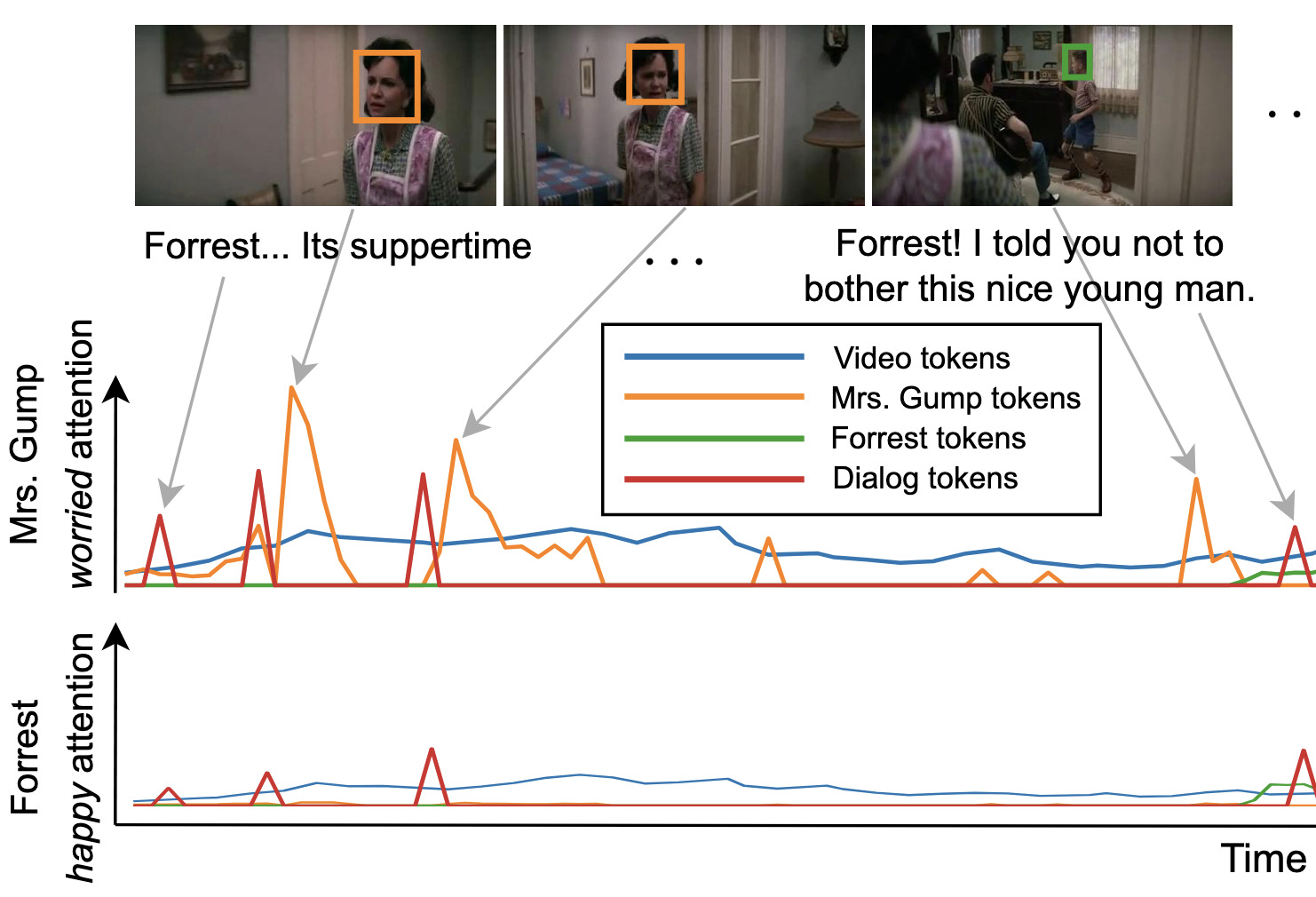 How you feelin’? Learning Emotions and Mental States in Movie ScenesDhruv Srivastava, Aditya Kumar Singh, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2023
How you feelin’? Learning Emotions and Mental States in Movie ScenesDhruv Srivastava, Aditya Kumar Singh, and Makarand TapaswiIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2023Movie story analysis requires understanding characters’ emotions and mental states. Towards this goal, we formulate emotion understanding as predicting a diverse and multi-label set of emotions at the level of a movie scene and for each character. We propose EmoTx, a multimodal Transformer-based architecture that ingests videos, multiple characters, and dialog utterances to make joint predictions. By leveraging annotations from the MovieGraphs dataset, we aim to predict classic emotions (e.g. happy, angry) and other mental states (e.g. honest, helpful). We conduct experiments on the most frequently occurring 10 and 25 labels, and a mapping that clusters 181 labels to 26. Ablation studies and comparison against adapted state-of-the-art emotion recognition approaches shows the effectiveness of EmoTx. Analyzing EmoTx’s self-attention scores reveals that expressive emotions often look at character tokens while other mental states rely on video and dialog cues.
@inproceedings{srivastava2023emotx, author = {Srivastava, Dhruv and Singh, Aditya Kumar and Tapaswi, Makarand}, title = {{How you feelin'? Learning Emotions and Mental States in Movie Scenes}}, year = {2023}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR52729.2023.00248} } - [C37]
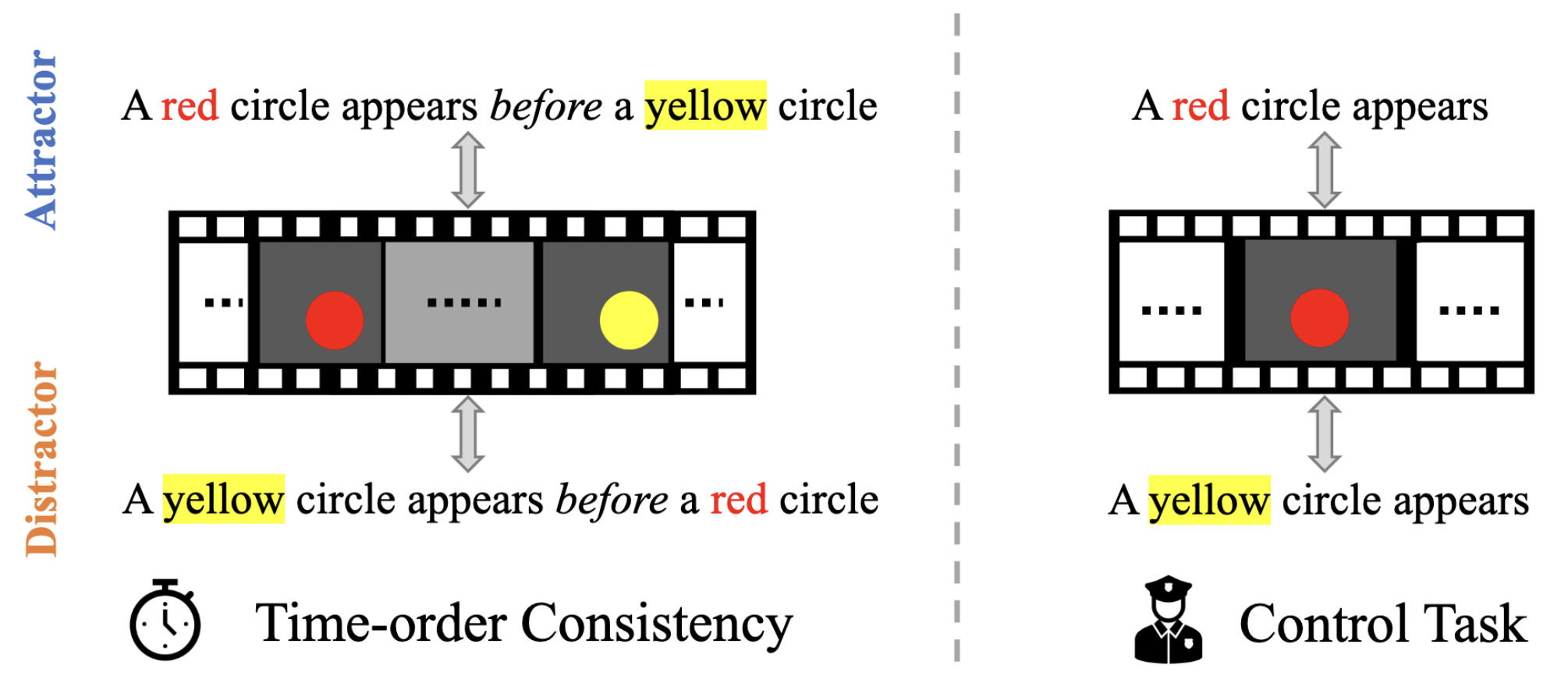 Test of Time: Instilling Video-Language Models with a Sense of TimePiyush Bagad, Makarand Tapaswi, and Cees G M SnoekIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2023
Test of Time: Instilling Video-Language Models with a Sense of TimePiyush Bagad, Makarand Tapaswi, and Cees G M SnoekIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2023Modeling and understanding time remains a challenge in contemporary video understanding models. With language emerging as a key driver towards powerful generalization, it is imperative for foundational video-language models to have a sense of time. In this paper, we consider a specific aspect of temporal understanding: consistency of time order as elicited by before/after relations. We establish that six existing video-language models struggle to understand even such simple temporal relations. We then question whether it is feasible to equip these foundational models with temporal awareness without re-training them from scratch. Towards this, we propose a temporal adaptation recipe on top of one such model, VideoCLIP, based on post-pretraining on a small amount of video-text data. We conduct a zero-shot evaluation of the adapted models on six datasets for three downstream tasks which require a varying degree of time awareness. We observe encouraging performance gains especially when the task needs higher time awareness. Our work serves as a first step towards probing and instilling a sense of time in existing video-language models without the need for data and compute-intense training from scratch.
@inproceedings{bagad2023testoftime, author = {Bagad, Piyush and Tapaswi, Makarand and Snoek, Cees G M}, title = {{Test of Time: Instilling Video-Language Models with a Sense of Time}}, year = {2023}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR52729.2023.00247} } - [W9]
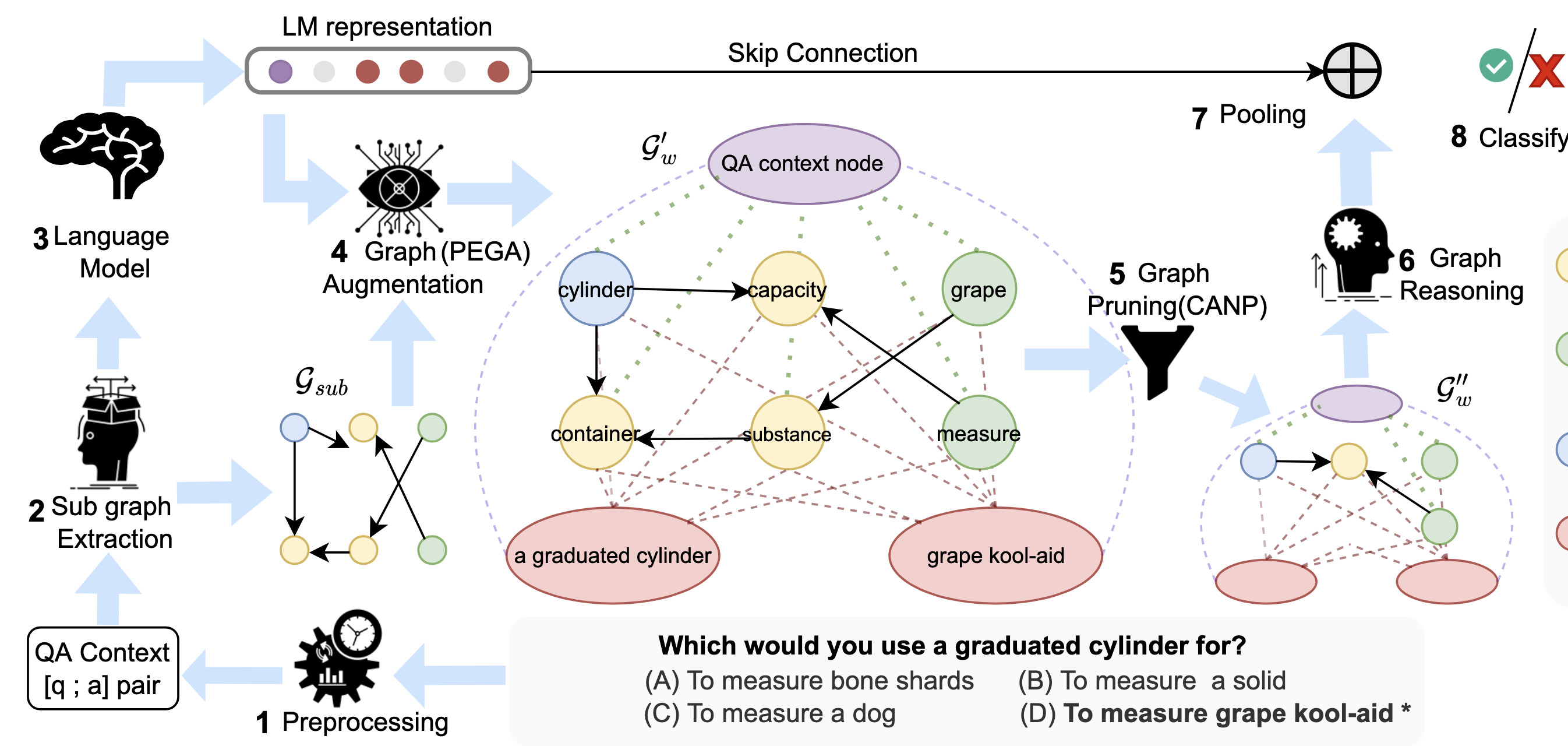 GrapeQA: GRaph Augmentation and Pruning to Enhance Question-AnsweringIn WWW Workshop on Natural Language Processing for Knowledge Graph Construction (NLP4KGc), May 2023
GrapeQA: GRaph Augmentation and Pruning to Enhance Question-AnsweringIn WWW Workshop on Natural Language Processing for Knowledge Graph Construction (NLP4KGc), May 2023Commonsense question-answering (QA) methods combine the power of pre-trained Language Models (LM) with the reasoning provided by Knowledge Graphs (KG). A typical approach collects nodes relevant to the QA pair from a KG to form a Working Graph (WG) followed by reasoning using Graph Neural Networks(GNNs). This faces two major challenges: (i) it is difficult to capture all the information from the QA in the WG, and (ii) the WG contains some irrelevant nodes from the KG. To address these, we propose GrapeQA with two simple improvements on the WG: (i) Prominent Entities for Graph Augmentation identifies relevant text chunks from the QA pair and augments the WG with corresponding latent representations from the LM, and (ii) Context-Aware Node Pruning removes nodes that are less relevant to the QA pair. We evaluate our results on OpenBookQA, CommonsenseQA and MedQA-USMLE and see that GrapeQA shows consistent improvements over its LM + KG predecessor (QA-GNN in particular) and large improvements on OpenBookQA.
@inproceedings{taunk2023grapeqa, author = {Taunk, Dhaval and Khanna, Lakshya and Kandru, Pavan and Varma, Vasudeva and Sharma, Charu and Tapaswi, Makarand}, title = {{GrapeQA: GRaph Augmentation and Pruning to Enhance Question-Answering}}, year = {2023}, booktitle = {WWW Workshop on Natural Language Processing for Knowledge Graph Construction (NLP4KGc)}, month = may, doi = {10.1145/3543873.3587651} } - [C36]
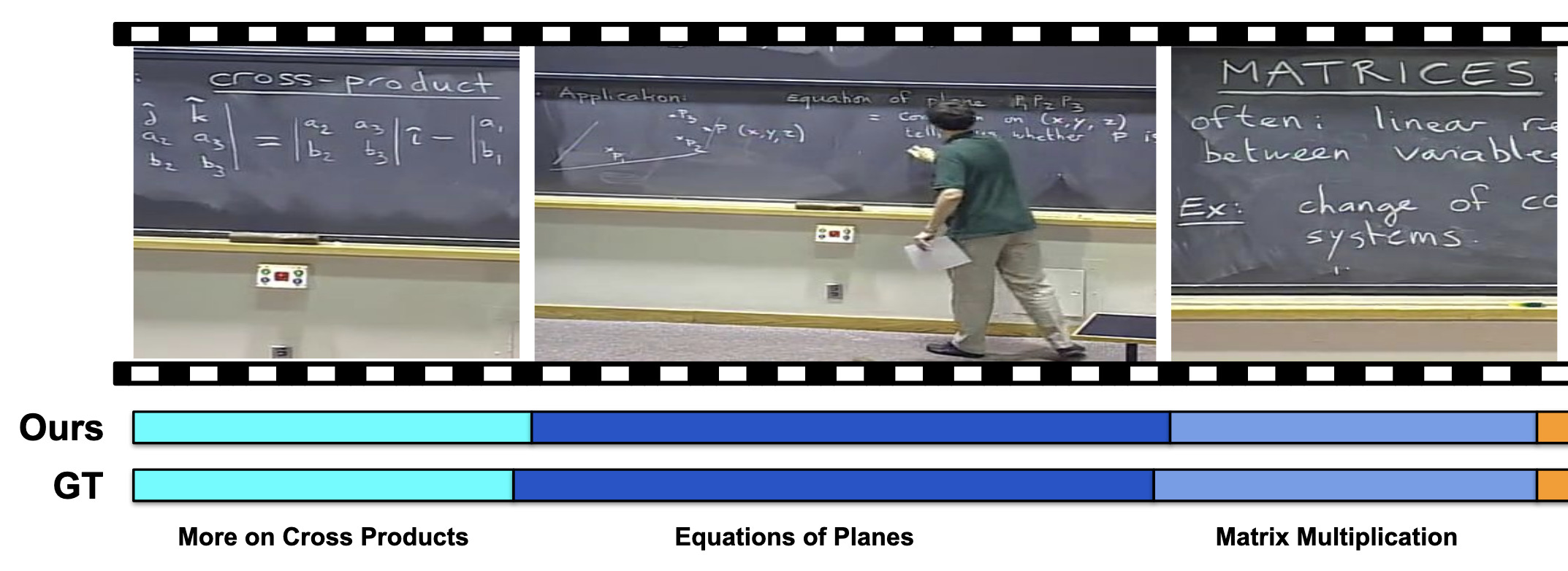 Unsupervised Audio-Visual Lecture SegmentationIn Winter Conference on Applications of Computer Vision (WACV), Jan 2023
Unsupervised Audio-Visual Lecture SegmentationIn Winter Conference on Applications of Computer Vision (WACV), Jan 2023Over the last decade, online lecture videos have become increasingly popular and have experienced a meteoric rise during the pandemic. However, video-language research has primarily focused on instructional videos or movies, and tools to help students navigate the growing online lectures are lacking. Our first contribution is to facilitate research in the educational domain by introducing AVLectures, a large-scale dataset consisting of 86 courses with over 2,350 lectures covering various STEM subjects. Each course contains video lectures, transcripts, OCR outputs for lecture frames, and optionally lecture notes, slides, assignments, and related educational content that can inspire a variety of tasks. Our second contribution is introducing video lecture segmentation that splits lectures into bite-sized topics. Lecture clip representations leverage visual, textual, and OCR cues and are trained on a pretext self-supervised task of matching the narration with the temporally aligned visual content. We formulate lecture segmentation as an unsupervised task and use these representations to generate segments using a temporally consistent 1-nearest neighbor algorithm, TW-FINCH. We evaluate our method on 15 courses and compare it against various visual and textual baselines, outperforming all of them. Our comprehensive ablation studies also identify the key factors driving the success of our approach.
@inproceedings{singh2023avlectures, author = {Singh, Darshan and Gupta, Anchit and Jawahar, C V and Tapaswi, Makarand}, title = {{Unsupervised Audio-Visual Lecture Segmentation}}, year = {2023}, booktitle = {Winter Conference on Applications of Computer Vision (WACV)}, month = jan, doi = {10.1109/WACV56688.2023.00520} }




2022
- [C35]
 Sonus Texere! Automated Dense Soundtrack Construction for Books using Movie AdaptationsJaidev Shriram, Makarand Tapaswi, and Vinoo AlluriIn International Society for Music Information Retrieval Conference (ISMIR), Dec 2022🏆 Brave New Idea Award
Sonus Texere! Automated Dense Soundtrack Construction for Books using Movie AdaptationsJaidev Shriram, Makarand Tapaswi, and Vinoo AlluriIn International Society for Music Information Retrieval Conference (ISMIR), Dec 2022🏆 Brave New Idea AwardReading, much like music listening, is an immersive experience that transports readers while taking them on an emotional journey. Listening to complementary music has the potential to amplify the reading experience, especially when the music is stylistically cohesive and emotionally relevant. In this paper, we propose the first fully automatic method to build a dense soundtrack for books, which can play high-quality instrumental music for the entirety of the reading duration. Our work employs a unique text processing and music weaving pipeline that determines the context and emotional composition of scenes in a chapter. This allows our method to identify and play relevant excerpts from the soundtrack of the book’s movie adaptation. By relying on the movie composer’s craftsmanship, our book soundtracks include expert-made motifs and other scene-specific musical characteristics. We validate the design decisions of our approach through a perceptual study. Our readers note that the book soundtrack greatly enhanced their reading experience, due to high immersiveness granted via uninterrupted and style-consistent music, and a heightened emotional state attained via high precision emotion and scene context recognition.
@inproceedings{shriram2025bookmusic, author = {Shriram, Jaidev and Tapaswi, Makarand and Alluri, Vinoo}, title = {{Sonus Texere! Automated Dense Soundtrack Construction for Books using Movie Adaptations}}, year = {2022}, booktitle = {International Society for Music Information Retrieval Conference (ISMIR)}, month = dec } - [C34]
 Grounded Video Situation RecognitionZeeshan Khan, C V Jawahar, and Makarand TapaswiIn Neural Information Processing Systems (NeurIPS), Dec 2022
Grounded Video Situation RecognitionZeeshan Khan, C V Jawahar, and Makarand TapaswiIn Neural Information Processing Systems (NeurIPS), Dec 2022Dense video understanding requires answering several questions such as who is doing what to whom, with what, how, why, and where. Recently, Video Situation Recognition (VidSitu) is framed as a task for structured prediction of multiple events, their relationships, and actions and various verb-role pairs attached to descriptive entities. This task poses several challenges in identifying, disambiguating, and co-referencing entities across multiple verb-role pairs, but also faces some challenges of evaluation. In this work, we propose the addition of spatio-temporal grounding as an essential component of the structured prediction task in a weakly supervised setting, and present a novel three stage Transformer model, VideoWhisperer, that is empowered to make joint predictions. In stage one, we learn contextualised embeddings for video features in parallel with key objects that appear in the video clips to enable fine-grained spatio-temporal reasoning. The second stage sees verb-role queries attend and pool information from object embeddings, localising answers to questions posed about the action. The final stage generates these answers as captions to describe each verb-role pair present in the video. Our model operates on a group of events (clips) simultaneously and predicts verbs, verb-role pairs, their nouns, and their grounding on-the-fly. When evaluated on a grounding-augmented version of the VidSitu dataset, we observe a large improvement in entity captioning accuracy, as well as the ability to localize verb-roles without grounding annotations at training time.
@inproceedings{khan2022gvsr, author = {Khan, Zeeshan and Jawahar, C V and Tapaswi, Makarand}, title = {{Grounded Video Situation Recognition}}, year = {2022}, booktitle = {Neural Information Processing Systems (NeurIPS)}, month = dec } - [C33]
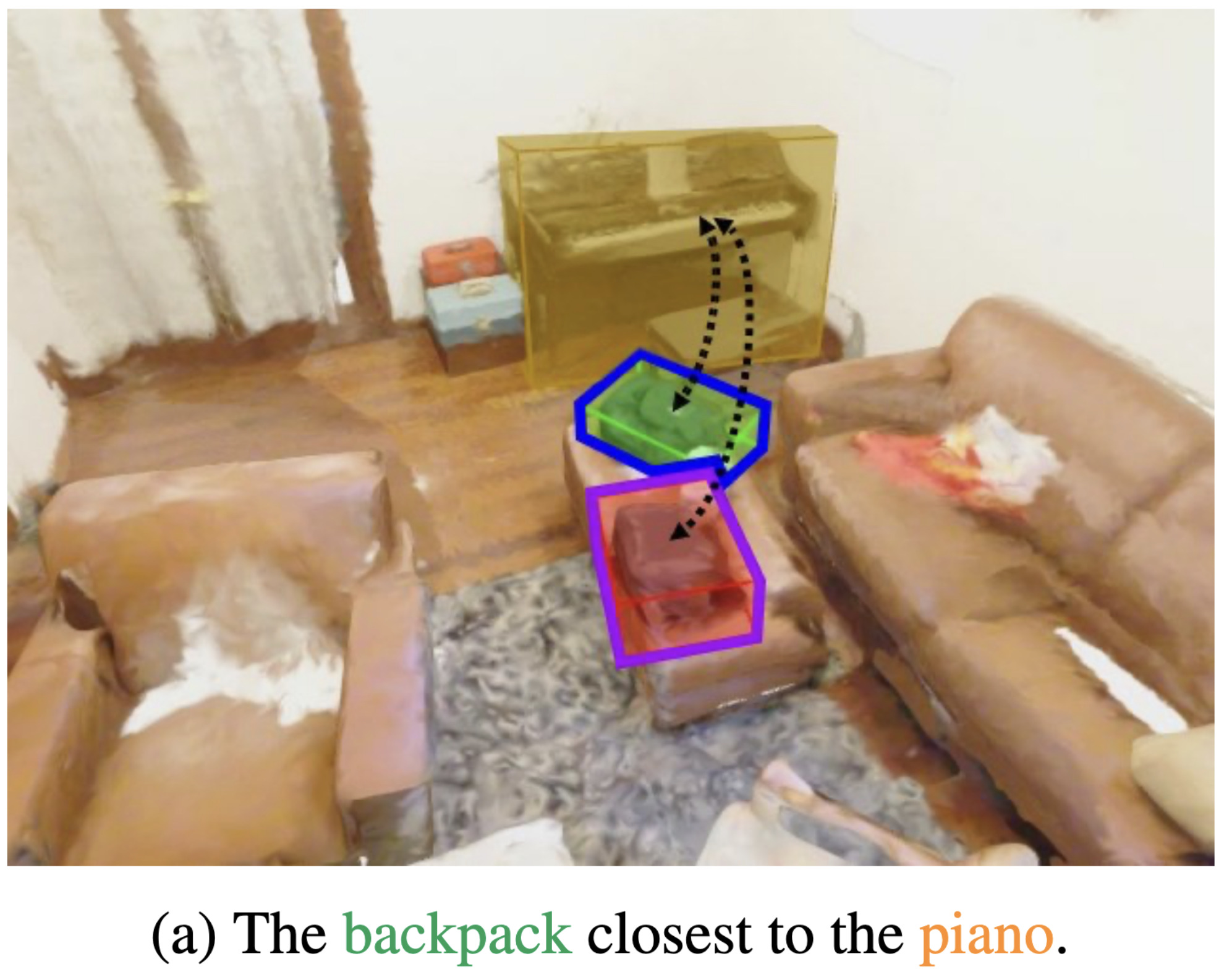 Language Conditioned Spatial Relation Reasoning for 3D Object GroundingIn Neural Information Processing Systems (NeurIPS), Dec 2022
Language Conditioned Spatial Relation Reasoning for 3D Object GroundingIn Neural Information Processing Systems (NeurIPS), Dec 2022Localizing objects in 3D scenes based on natural language requires understanding and reasoning about spatial relations. In particular, it is often crucial to distinguish similar objects referred by the text, such as "the left most chair" and "a chair next to the window". In this work we propose a language-conditioned transformer model for grounding 3D objects and their spatial relations. To this end, we design a spatial self-attention layer that accounts for relative distances and orientations between objects in input 3D point clouds. Training such a layer with visual and language inputs enables to disambiguate spatial relations and to localize objects referred by the text. To facilitate the cross-modal learning of relations, we further propose a teacher-student approach where the teacher model is first trained using ground-truth object labels, and then helps to train a student model using point cloud inputs. We perform ablation studies showing advantages of our approach. We also demonstrate our model to significantly outperform the state of the art on the challenging Nr3D, Sr3D and ScanRefer 3D object grounding datasets. Our code and pretrained models will become publicly available.
@inproceedings{chen20223dvg, author = {Chen, Shizhe and Guhur, Pierre-Louis and Tapaswi, Makarand and Schmid, Cordelia and Laptev, Ivan}, title = {{Language Conditioned Spatial Relation Reasoning for 3D Object Grounding}}, year = {2022}, booktitle = {Neural Information Processing Systems (NeurIPS)}, month = dec } - [W8]
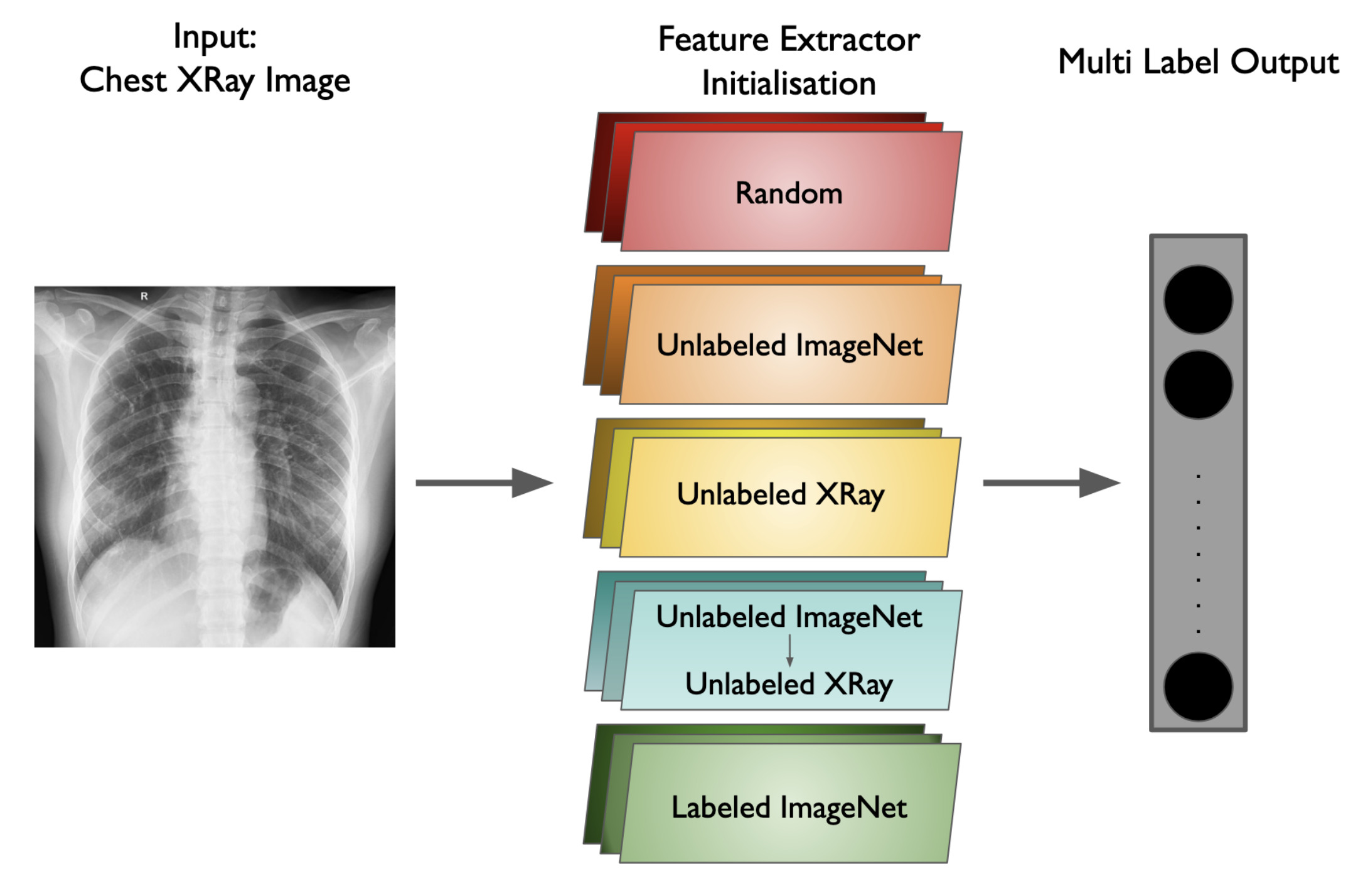 Can we Adopt Self-supervised Pretraining for Chest X-Rays?Arsh Verma, and Makarand TapaswiIn Machine Learning for Healthcare (ML4H) (Extended Abstract), Nov 2022
Can we Adopt Self-supervised Pretraining for Chest X-Rays?Arsh Verma, and Makarand TapaswiIn Machine Learning for Healthcare (ML4H) (Extended Abstract), Nov 2022Chest radiograph (or Chest X-Ray, CXR) is a popular medical imaging modality that is used by radiologists across the world to diagnose heart or lung conditions. Over the last decade, Convolutional Neural Networks (CNN), have seen success in identifying pathologies in CXR images. Typically, these CNNs are pretrained on the standard ImageNet classification task, but this assumes availability of large-scale annotated datasets. In this work, we analyze the utility of pretraining on unlabeled ImageNet or Chest X-Ray (CXR) datasets using various algorithms and in multiple settings. Some findings of our work include: (i) supervised training with labeled ImageNet learns strong representations that are hard to beat; (ii) self-supervised pretraining on ImageNet ( 1M images) shows performance similar to self-supervised pretraining on a CXR dataset ( 100K images); and (iii) the CNN trained on supervised ImageNet can be trained further with self-supervised CXR images leading to improvements, especially when the downstream dataset is on the order of a few thousand images.
@inproceedings{verma2022sslcxr, author = {Verma, Arsh and Tapaswi, Makarand}, title = {{Can we Adopt Self-supervised Pretraining for Chest X-Rays?}}, year = {2022}, booktitle = {Machine Learning for Healthcare (ML4H) (Extended Abstract)}, month = nov } - [C32]
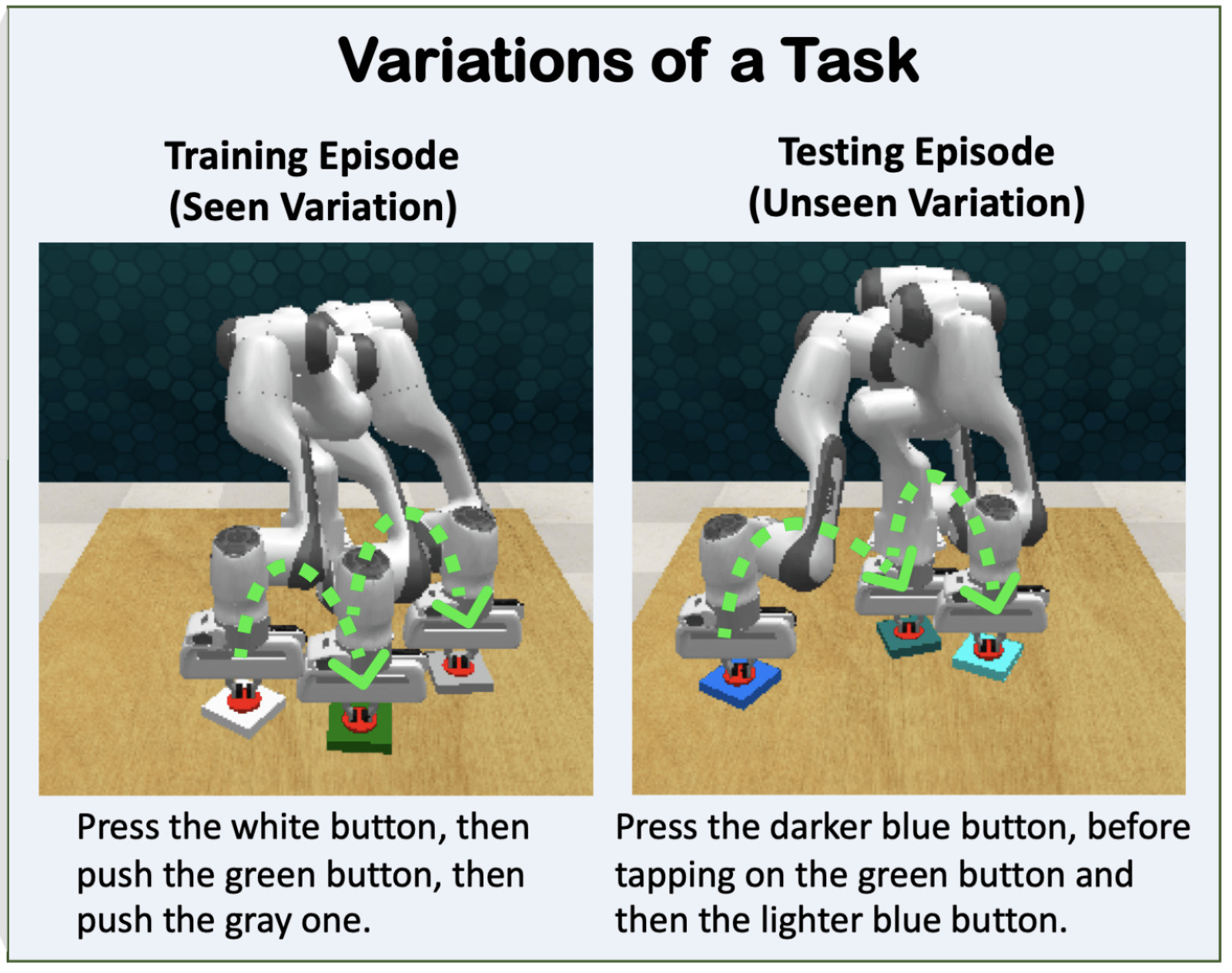 Instruction-driven History-aware Policies for Robotic ManipulationsPierre-Louis Guhur, Shizhe Chen, Ricardo Garcia Pinel, Makarand Tapaswi, Ivan Laptev, and Cordelia SchmidIn Conference on Robot Learning (CoRL), Dec 2022
Instruction-driven History-aware Policies for Robotic ManipulationsPierre-Louis Guhur, Shizhe Chen, Ricardo Garcia Pinel, Makarand Tapaswi, Ivan Laptev, and Cordelia SchmidIn Conference on Robot Learning (CoRL), Dec 2022In human environments, robots are expected to accomplish a variety of manipulation tasks given simple natural language instructions. Yet, robotic manipulation is extremely challenging as it requires fine-grained motor control, long-term memory as well as generalization to previously unseen tasks and environments. To address these challenges, we propose a unified transformer-based approach that takes into account multiple inputs. In particular, our transformer architecture integrates (i) natural language instructions and (ii) multi-view scene observations while (iii) keeping track of the full history of observations and actions. Such an approach enables learning dependencies between history and instructions and improves manipulation precision using multiple views. We evaluate our method on the challenging RLBench benchmark and on a real-world robot. Notably, our approach scales to 74 diverse RLBench tasks and outperforms the state of the art. We also address instruction-conditioned tasks and demonstrate excellent generalization to previously unseen variations.
@inproceedings{guhur2022hiveformer, author = {Guhur, Pierre-Louis and Chen, Shizhe and Pinel, Ricardo Garcia and Tapaswi, Makarand and Laptev, Ivan and Schmid, Cordelia}, title = {{Instruction-driven History-aware Policies for Robotic Manipulations}}, year = {2022}, booktitle = {Conference on Robot Learning (CoRL)}, month = dec } - [C31]
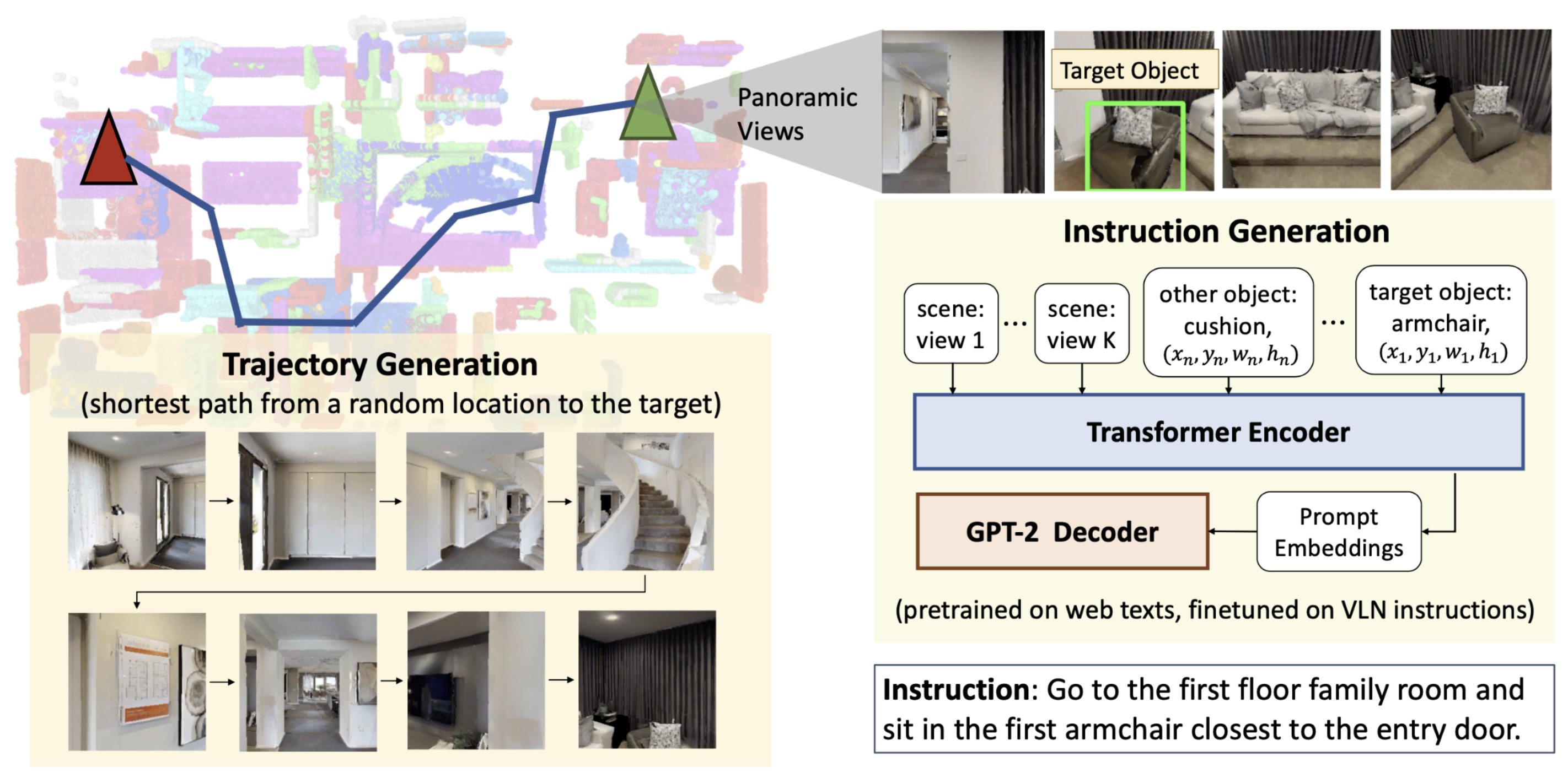 Learning from Unlabeled 3D Environments for Vision-and-Language NavigationIn European Conference on Computer Vision (ECCV), Oct 2022
Learning from Unlabeled 3D Environments for Vision-and-Language NavigationIn European Conference on Computer Vision (ECCV), Oct 2022In vision-and-language navigation (VLN), an embodied agent is required to navigate in realistic 3D environments following natural language instructions. One major bottleneck for existing VLN approaches is the lack of sufficient training data, resulting in unsatisfactory generalization to unseen environments. While VLN data is typically collected manually, such an approach is expensive and prevents scalability. In this work, we address the data scarcity issue by proposing to automatically create a large-scale VLN dataset from 900 unlabeled 3D buildings from HM3D. We generate a navigation graph for each building and transfer object predictions from 2D to generate pseudo 3D object labels by cross-view consistency. We then fine-tune a pretrained language model using pseudo object labels as prompts to alleviate the cross-modal gap in instruction generation. Our resulting HM3D-AutoVLN dataset is an order of magnitude larger than existing VLN datasets in terms of navigation environments and instructions. We experimentally demonstrate that HM3D-AutoVLN significantly increases the generalization ability of resulting VLN models. On the SPL metric, our approach improves over state of the art by 7.1% and 8.1% on the unseen validation splits of REVERIE and SOON datasets respectively.
@inproceedings{chen20223dvln, author = {Chen, Shizhe and Guhur, Pierre-Louis and Tapaswi, Makarand and Schmid, Cordelia and Laptev, Ivan}, title = {{Learning from Unlabeled 3D Environments for Vision-and-Language Navigation}}, year = {2022}, booktitle = {European Conference on Computer Vision (ECCV)}, month = oct } - [C30]
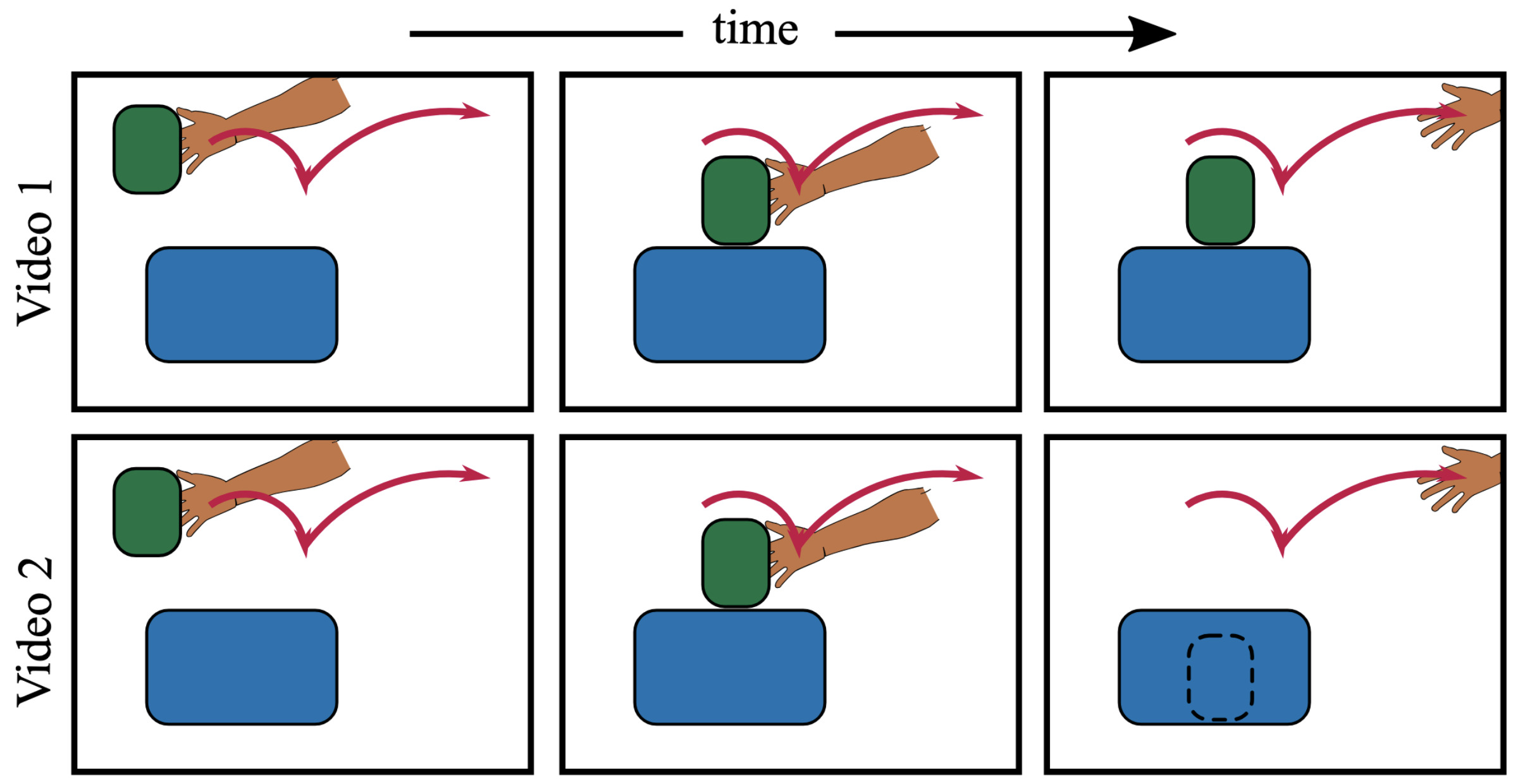 Learning Object Manipulation Skills from Video via Approximate Differentiable PhysicsIn International Conference on Intelligent Robots and Systems (IROS), Oct 2022
Learning Object Manipulation Skills from Video via Approximate Differentiable PhysicsIn International Conference on Intelligent Robots and Systems (IROS), Oct 2022We aim to teach robots to perform simple object manipulation tasks by watching a single video demonstration. Towards this goal, we propose an optimization approach that outputs a coarse and temporally evolving 3D scene to mimic the action demonstrated in the input video. Similar to previous work, a differentiable renderer ensures perceptual fidelity between the 3D scene and the 2D video. Our key novelty lies in the inclusion of a differentiable approach to solve a set of Ordinary Differential Equations (ODEs) that allows us to approximately model laws of physics such as gravity, friction, and hand-object or object-object interactions. This not only enables us to dramatically improve the quality of estimated hand and object states, but also produces physically admissible trajectories that can be directly translated to a robot without the need for costly reinforcement learning. We evaluate our approach on a 3D reconstruction task that consists of 54 video demonstrations sourced from 9 actions such as pull something from right to left or put something in front of something. Our approach improves over previous state-of-the-art by almost 30%, demonstrating superior quality on especially challenging actions involving physical interactions of two objects such as put something onto something. Finally, we showcase the learned skills on a Franka Emika Panda robot.
@inproceedings{petrik2022physicsreal2sim, author = {Petrik, Vladimir and Qureshi, Mohammad Nomaan and Sivic, Josef and Tapaswi, Makarand}, title = {{Learning Object Manipulation Skills from Video via Approximate Differentiable Physics}}, year = {2022}, booktitle = {International Conference on Intelligent Robots and Systems (IROS)}, month = oct } - [C29]
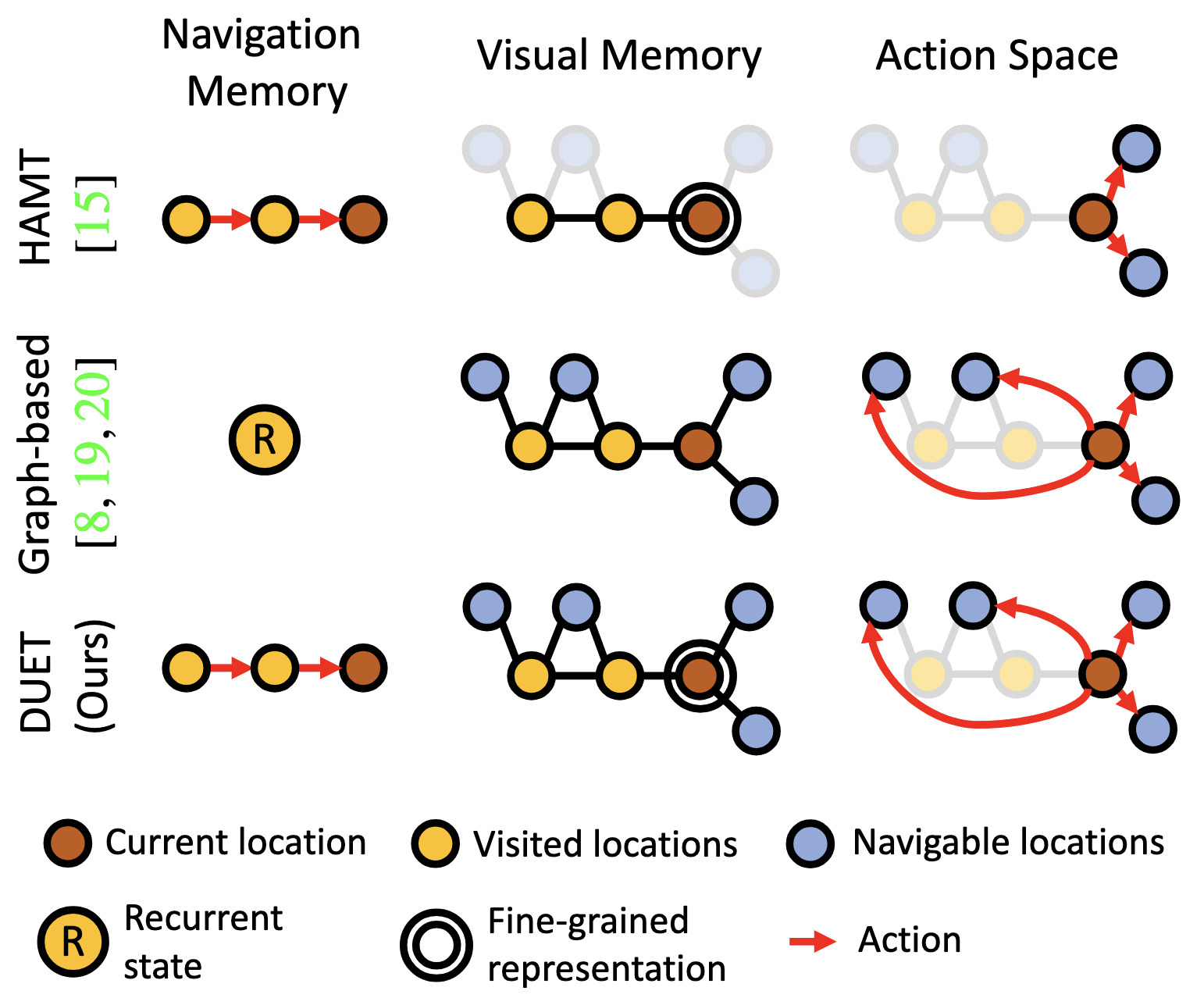 Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language NavigationIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022
Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language NavigationIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022Following language instructions to navigate in unseen environments is a challenging problem for autonomous embodied agents. The agent not only needs to ground languages in visual scenes, but also should explore the environment to reach its target. In this work, we propose a dual-scale graph transformer (DUET) for joint long-term action planning and fine-grained cross-modal understanding. We build a topological map on-the-fly to enable efficient exploration in global action space. To balance the complexity of large action space reasoning and fine-grained language grounding, we dynamically combine a fine-scale encoding over local observations and a coarse-scale encoding on a global map via graph transformers. The proposed approach, DUET, significantly outperforms state-of-the-art methods on goal-oriented vision-and-language navigation (VLN) benchmarks REVERIE and SOON. It also improves the success rate on the fine-grained VLN benchmark R2R.
@inproceedings{chen2022duet, author = {Chen, Shizhe and Guhur, Pierre-Louis and Tapaswi, Makarand and Schmid, Cordelia and Laptev, Ivan}, title = {{Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation}}, year = {2022}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR52688.2022.01604} }








2021
- [J3]
 Long term Spatio-Temporal Modeling for Action DetectionMakarand Tapaswi* , Vijay Kumar*, and Ivan LaptevComputer Vision and Image Understanding (CVIU), Jun 2021
Long term Spatio-Temporal Modeling for Action DetectionMakarand Tapaswi* , Vijay Kumar*, and Ivan LaptevComputer Vision and Image Understanding (CVIU), Jun 2021Modeling person interactions with their surroundings has proven to be effective for recognizing and localizing human actions in videos. While most recent works focus on learning short term interactions, in this work, we consider long-term person interactions and jointly localize actions of multiple actors over an entire video shot. We construct a graph with nodes that correspond to keyframe actor instances and connect them with two edge types. Spatial edges connect actors within a keyframe, and temporal edges connect multiple instances of the same actor over a video shot. We propose a Graph Neural Network that explicitly models spatial and temporal states for each person instance and learns to effectively combine information from both modalities to make predictions at the same time. We conduct experiments on the AVA dataset and show that our graph-based model provides consistent improvements over several video descriptors, achieving state-of-the-art performance without any fine-tuning.
@article{tapaswi2021avagnn, author = {Tapaswi, Makarand and Kumar, Vijay and Laptev, Ivan}, title = {{Long term Spatio-Temporal Modeling for Action Detection}}, year = {2021}, journal = {Computer Vision and Image Understanding (CVIU)}, volume = {210}, doi = {10.1016/j.cviu.2021.103242} } - [C28]
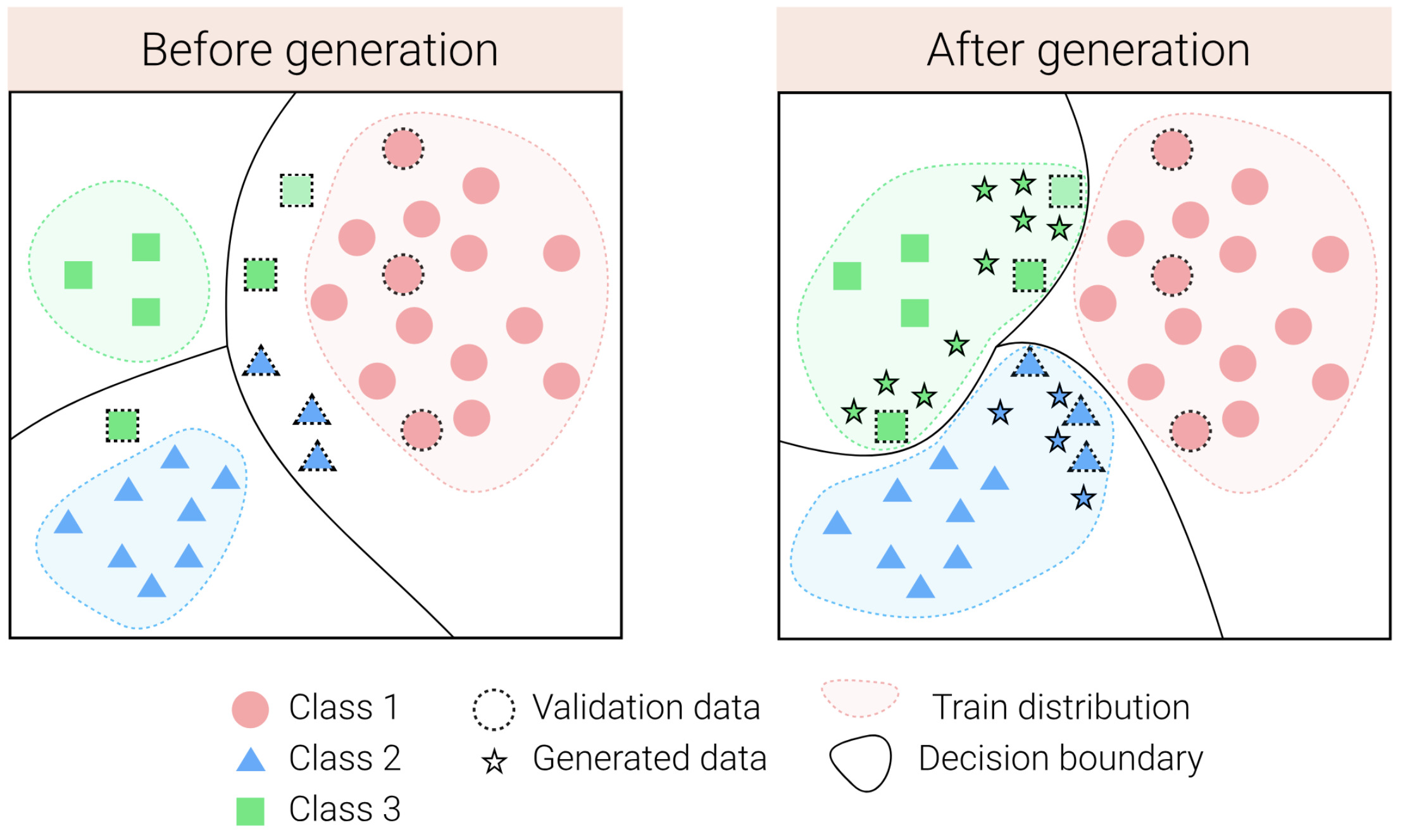 Feature Generation for Long-tail ClassificationIn Indian Conference on Computer Vision, Graphics, and Image Processing (ICVGIP), Dec 2021
Feature Generation for Long-tail ClassificationIn Indian Conference on Computer Vision, Graphics, and Image Processing (ICVGIP), Dec 2021The visual world naturally exhibits an imbalance in the number of object or scene instances resulting in a long-tailed distribution. This imbalance poses significant challenges for classification models based on deep learning. Oversampling instances of the tail classes attempts to solve this imbalance. However, the limited visual diversity results in a network with poor representation ability. A simple counter to this is decoupling the representation and classifier networks and using oversampling only to train the classifier. In this paper, instead of repeatedly re-sampling the same image (and thereby features), we explore a direction that attempts to generate meaningful features by estimating the tail category’s distribution. Inspired by ideas from recent work on few-shot learning, we create calibrated distributions to sample additional features that are subsequently used to train the classifier. Through several experiments on the CIFAR-100-LT (long-tail) dataset with varying imbalance factors and on mini-ImageNet-LT (long-tail), we show the efficacy of our approach and establish a new state-of-the-art. We also present a qualitative analysis of generated features using t-SNE visualizations and analyze the nearest neighbors used to calibrate the tail class distributions. Our code is available at \urlhttps://github.com/rahulvigneswaran/TailCalibX.
@inproceedings{vigneswaran2021tailcalibx, author = {Vigneswaran, Rahul and Law, Marc T. and Balasubramanian, Vineeth N and Tapaswi, Makarand}, title = {{Feature Generation for Long-tail Classification}}, year = {2021}, booktitle = {Indian Conference on Computer Vision, Graphics, and Image Processing (ICVGIP)}, month = dec, doi = {10.1145/3490035.3490300} } - [C27]
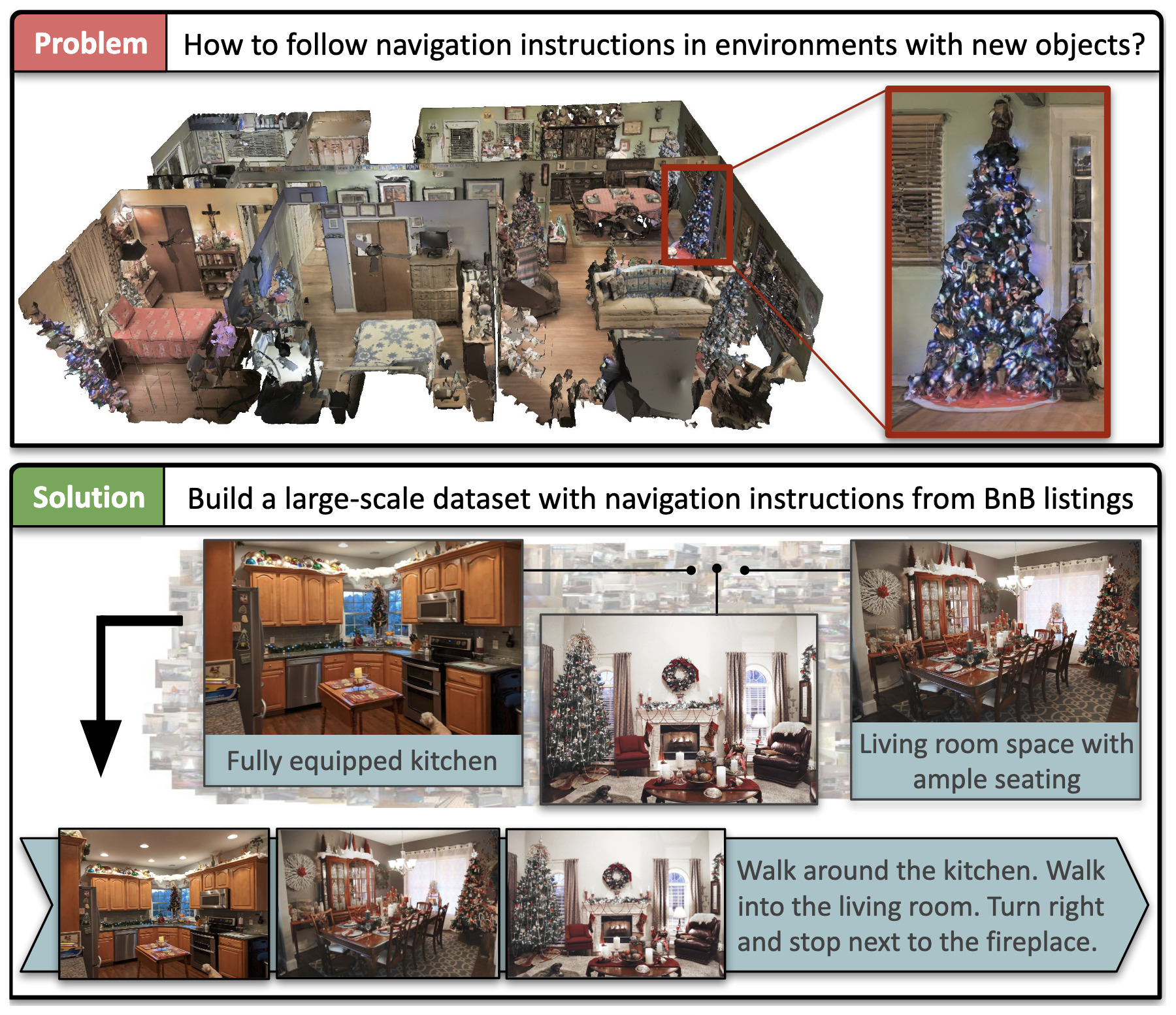 Airbert: In-domain Pretraining for Vision-and-Language NavigationIn International Conference on Computer Vision (ICCV), Oct 2021
Airbert: In-domain Pretraining for Vision-and-Language NavigationIn International Conference on Computer Vision (ICCV), Oct 2021Vision-and-language navigation (VLN) aims to enable embodied agents to navigate in realistic environments using natural language instructions. Given the scarcity of domain-specific training data and the high diversity of image and language inputs, the generalization of VLN agents to unseen environments remains challenging. Recent methods explore pretraining to improve generalization, however, the use of generic image-caption datasets or existing small-scale VLN environments is suboptimal and results in limited improvements. In this work, we introduce BnB, a large-scale and diverse in-domain VLN dataset. We first collect image-caption (IC) pairs from hundreds of thousands of listings from online rental marketplaces. Using IC pairs we next propose automatic strategies to generate millions of VLN path-instruction (PI) pairs. We further propose a shuffling loss that improves the learning of temporal order inside PI pairs. We use BnB to pretrain our Airbert model that can be adapted to discriminative and generative settings and show that it outperforms state of the art for Room-to-Room (R2R) navigation and Remote Referring Expression (REVERIE) benchmarks. Moreover, our in-domain pretraining significantly increases performance on a challenging few-shot VLN evaluation, where we train the model only on VLN instructions from a few houses.
@inproceedings{guhur2021airbert, author = {Guhur, Pierre-Louis and Tapaswi, Makarand and Chen, Shizhe and Schmid, Cordelia and Laptev, Ivan}, title = {{Airbert: In-domain Pretraining for Vision-and-Language Navigation}}, year = {2021}, booktitle = {International Conference on Computer Vision (ICCV)}, month = oct, doi = {10.1109/ICCV48922.2021.00166} }



2020
- [C26]
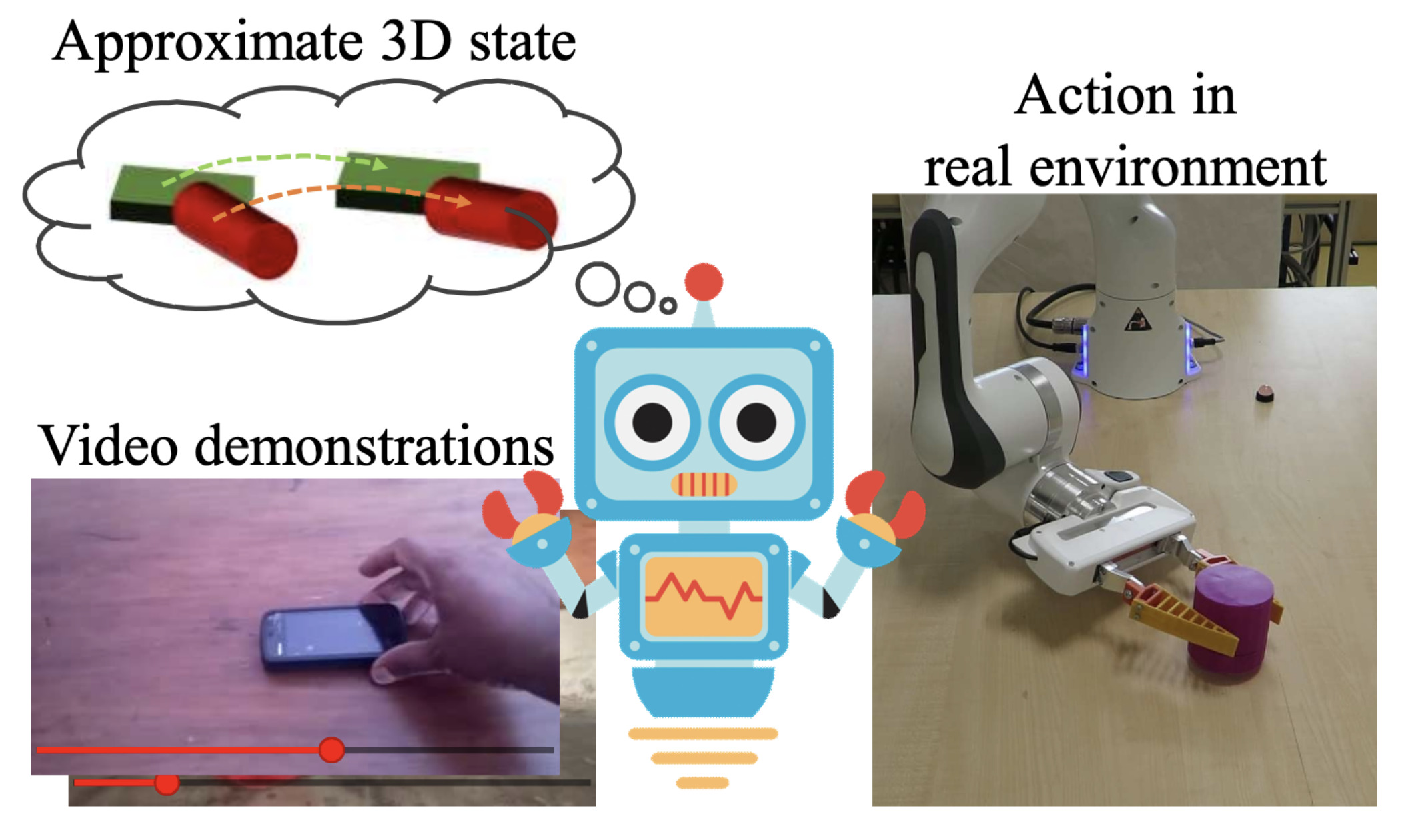 Learning Object Manipulation Skills via Approximate State Estimation from Real VideosIn Conference on Robot Learning (CoRL), Nov 2020
Learning Object Manipulation Skills via Approximate State Estimation from Real VideosIn Conference on Robot Learning (CoRL), Nov 2020Humans are adept at learning new tasks by watching a few instructional videos. On the other hand, robots that learn new actions either require a lot of effort through trial and error, or use expert demonstrations that are challenging to obtain. In this paper, we explore a method that facilitates learning object manipulation skills directly from videos. Leveraging recent advances in 2D visual recognition and differentiable rendering, we develop an optimization based method to estimate a coarse 3D state representation for the hand and the manipulated object(s) without requiring any supervision. We use these trajectories as dense rewards for an agent that learns to mimic them through reinforcement learning. We evaluate our method on simple single- and two-object actions from the Something-Something dataset. Our approach allows an agent to learn actions from single videos, while watching multiple demonstrations makes the policy more robust. We show that policies learned in a simulated environment can be easily transferred to a real robot.
@inproceedings{petrik2020real2sim, author = {Petrik, Vladimir and Tapaswi, Makarand and Laptev, Ivan and Sivic, Josef}, title = {{Learning Object Manipulation Skills via Approximate State Estimation from Real Videos}}, year = {2020}, booktitle = {Conference on Robot Learning (CoRL)}, month = nov } - [C25]
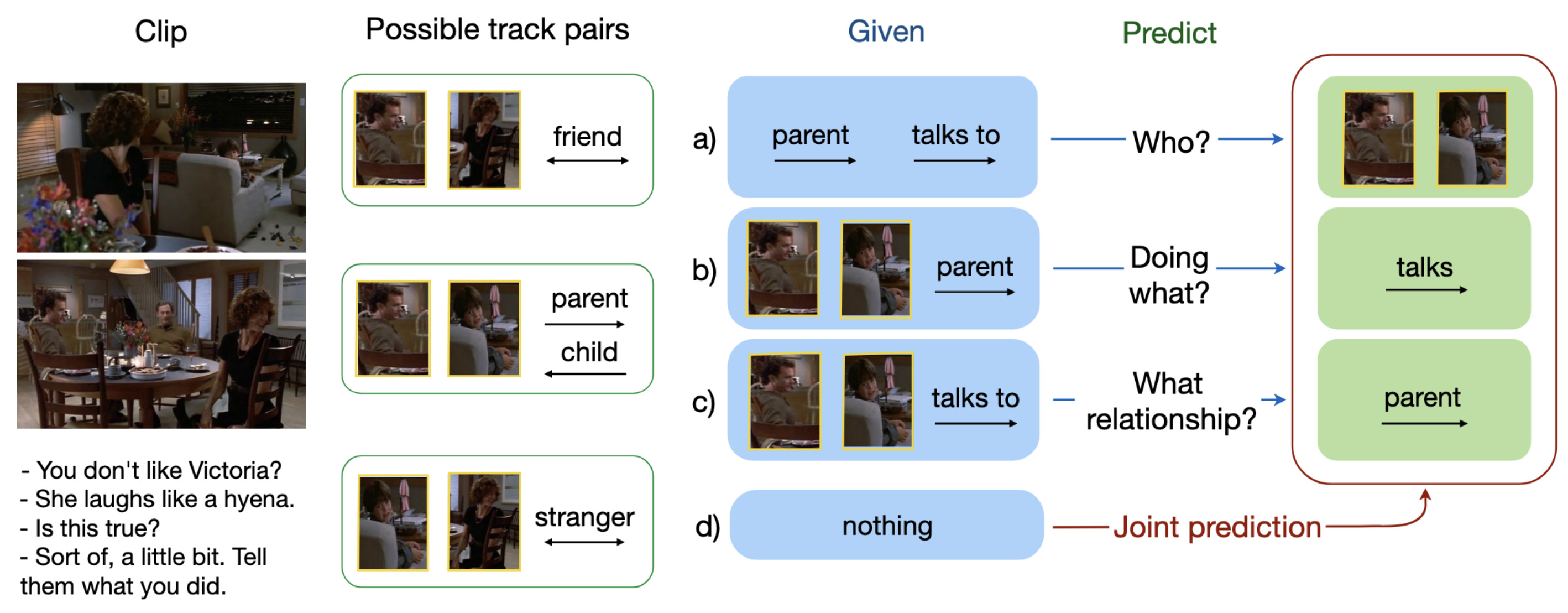 Learning Interactions and Relationships between Movie CharactersAnna Kukleva, Makarand Tapaswi, and Ivan LaptevIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2020
Learning Interactions and Relationships between Movie CharactersAnna Kukleva, Makarand Tapaswi, and Ivan LaptevIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2020Interactions between people are often governed by their relationships. On the flip side, social relationships are built upon several interactions. Two strangers are more likely to greet and introduce themselves while becoming friends over time. We are fascinated by this interplay between interactions and relationships, and believe that it is an important aspect of understanding social situations. In this work, we propose neural models to learn and jointly predict interactions, relationships, and the pair of characters that are involved. We note that interactions are informed by a mixture of visual and dialog cues, and present a multimodal architecture to extract meaningful information from them. Localizing the pair of interacting characters in video is a time-consuming process, instead, we train our model to learn from clip-level weak labels. We evaluate our models on the MovieGraphs dataset and show the impact of modalities, use of longer temporal context for predicting relationships, and achieve encouraging performance using weak labels as compared with ground-truth labels.
@inproceedings{kukleva2020mgintrel, author = {Kukleva, Anna and Tapaswi, Makarand and Laptev, Ivan}, title = {{Learning Interactions and Relationships between Movie Characters}}, year = {2020}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR42600.2020.00987} } - [C24]
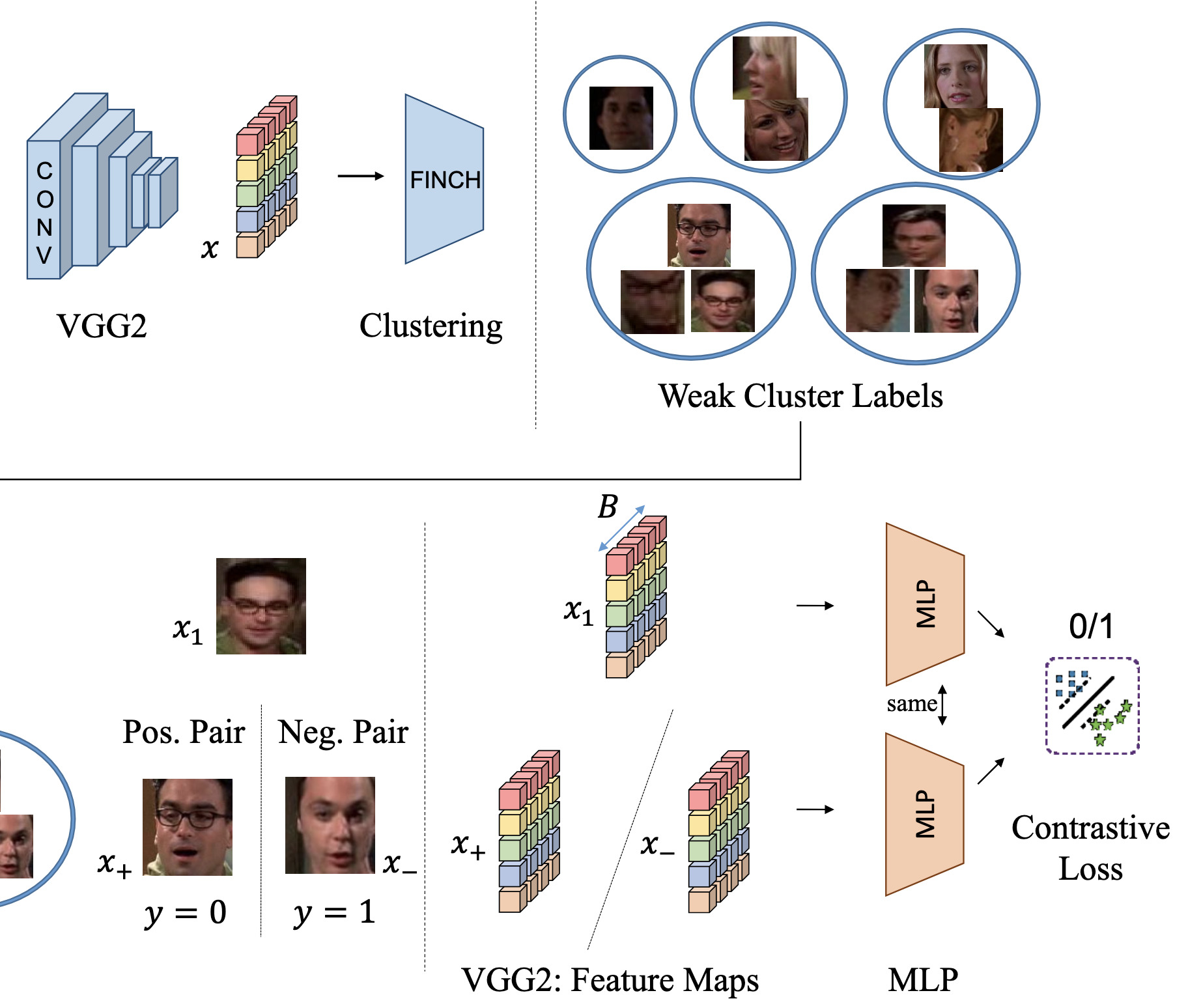 Clustering based Contrastive Learning for Improving Face RepresentationsIn IEEE International Conference on Automatic Face and Gesture Recognition (FG), May 2020
Clustering based Contrastive Learning for Improving Face RepresentationsIn IEEE International Conference on Automatic Face and Gesture Recognition (FG), May 2020A good clustering algorithm can discover natural groupings in data. These groupings, if used wisely, providea form of weak supervision for learning representations. In this work, we present Clustering-based Contrastive Learning (CCL), a new clustering-based representation learning approach that uses labels obtained from clustering along with video constraints to learn discriminative face features. We demonstrate our method on the challenging task of learning representations for video face clustering. Through several ablation studies, we analyze the impact of creating pair-wise positive and negative labels from different sources. Experiments on three challenging video face clustering datasets: BBT-0101, BF-0502, and ACCIO show that CCL achieves a new state-of-the-art on all datasets.
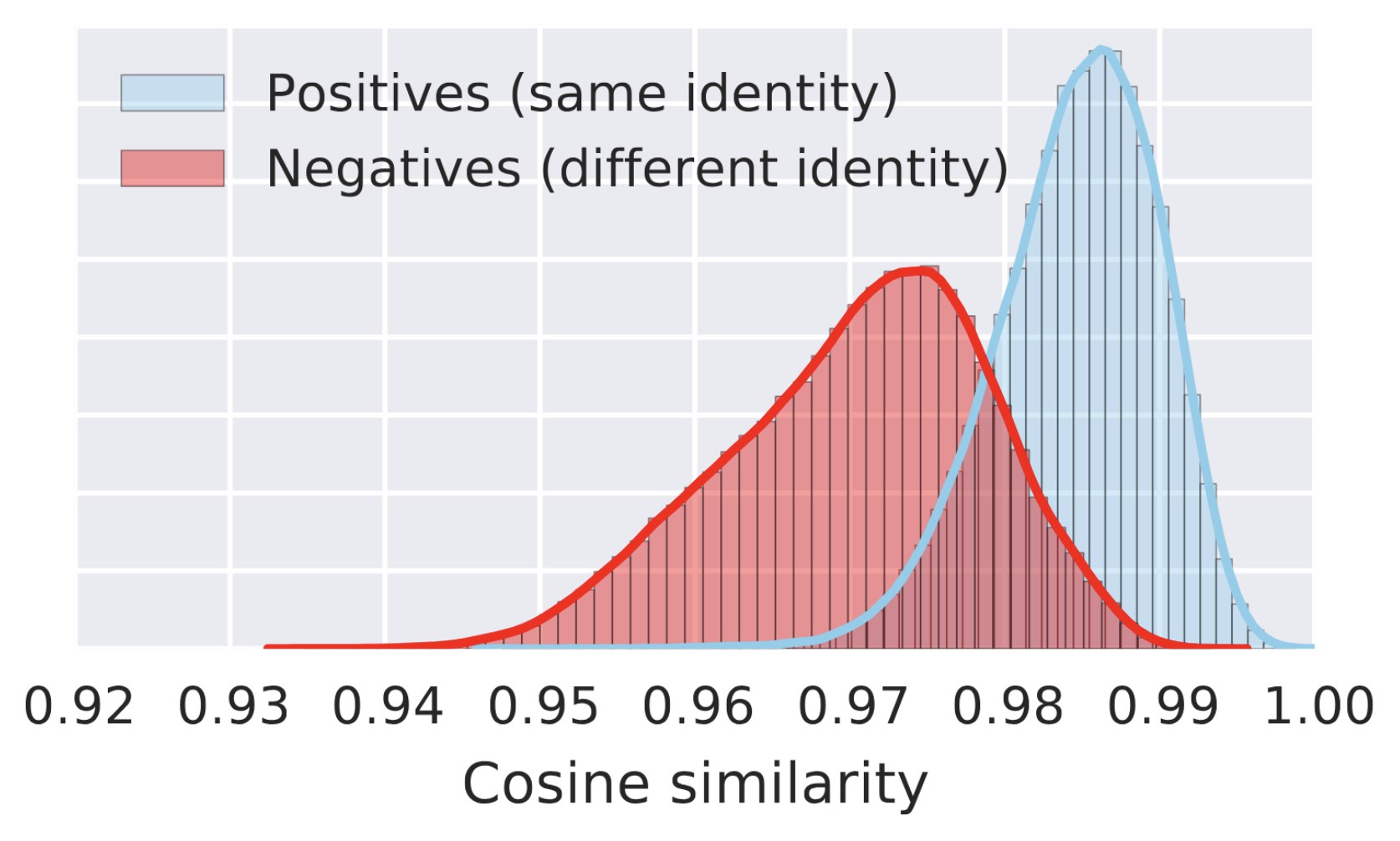
@inproceedings{sharma2020ccl, author = {Sharma, Vivek and Tapaswi, Makarand and Sarfraz, Saquib and Stiefelhagen, Rainer}, title = {{Clustering based Contrastive Learning for Improving Face Representations}}, year = {2020}, booktitle = {IEEE International Conference on Automatic Face and Gesture Recognition (FG)}, month = may, doi = {10.1109/FG47880.2020.00011} } - [J2] Video Face Clustering with Self-Supervised Representation LearningIEEE Transactions on Biometrics (T-BIOM), May 2020
Characters are a key component of understanding the story conveyed in TV series and movies. With the rise of advanced deep face models, identifying face images may seem like a solved problem. However, as face detectors get better, clustering and identification need to be revisited to address increasing diversity in facial appearance. In this paper, we propose unsupervised methods for feature refinement with application to video face clustering. Our emphasis is on distilling the essential information, identity, from the representations obtained using deep pre-trained face networks. We propose a self-supervised Siamese network that can be trained without the need for video/track based supervision, that can also be applied to image collections. We evaluate our methods on three video face clustering datasets. Thorough experiments including generalization studies show that our methods outperform current state-of-the-art methods on all datasets. The datasets and code are available at https://github.com/vivoutlaw/SSIAM.
@article{sharma2019tbiom, author = {Sharma, Vivek and Tapaswi, Makarand and Sarfraz, M. Saquib and Stiefelhagen, Rainer}, title = {{Video Face Clustering with Self-Supervised Representation Learning}}, year = {2020}, journal = {IEEE Transactions on Biometrics (T-BIOM)}, volume = {4}, pages = {145-157}, doi = {10.1109/TBIOM.2019.2947264} }



2019
- [C23]
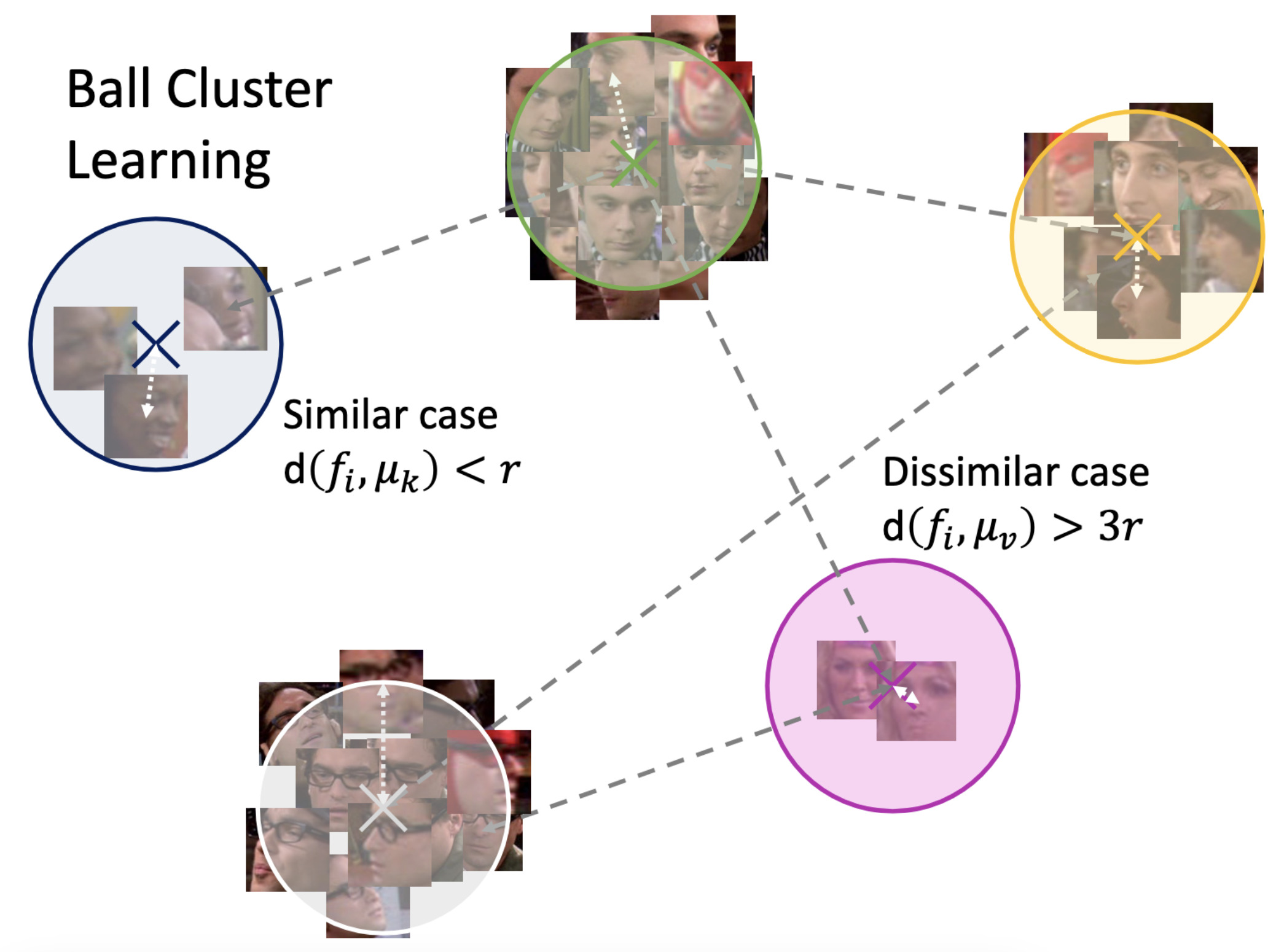 Video Face Clustering with Unknown Number of ClustersMakarand Tapaswi, Marc T. Law, and Sanja FidlerIn International Conference on Computer Vision (ICCV), Oct 2019
Video Face Clustering with Unknown Number of ClustersMakarand Tapaswi, Marc T. Law, and Sanja FidlerIn International Conference on Computer Vision (ICCV), Oct 2019Understanding videos such as TV series and movies requires analyzing who the characters are and what they are doing. We address the challenging problem of clustering face tracks based on their identity. Different from previous work in this area, we choose to operate in a realistic and difficult setting where: (i) the number of characters is not known a priori; and (ii) face tracks belonging to minor or background characters are not discarded. To this end, we propose Ball Cluster Learning (BCL), a supervised approach to carve the embedding space into balls of equal size, one for each cluster. The learned ball radius is easily translated to a stopping criterion for iterative merging algorithms. This gives BCL the ability to estimate the number of clusters as well as their assignment, achieving promising results on commonly used datasets. We also present a thorough discussion of how existing metric learning literature can be adapted for this task.
@inproceedings{tapaswi2019ballcluster, author = {Tapaswi, Makarand and Law, Marc T. and Fidler, Sanja}, title = {{Video Face Clustering with Unknown Number of Clusters}}, year = {2019}, booktitle = {International Conference on Computer Vision (ICCV)}, month = oct, doi = {10.1109/ICCV.2019.00513} } - [C22]
 HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video ClipsAntoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef SivicIn International Conference on Computer Vision (ICCV), Oct 2019
HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video ClipsAntoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef SivicIn International Conference on Computer Vision (ICCV), Oct 2019Learning text-video embeddings usually requires a dataset of video clips with manually provided captions. However, such datasets are expensive and time consuming to create and therefore difficult to obtain on a large scale. In this work, we propose instead to learn such embeddings from video data with readily available natural language annotations in the form of automatically transcribed narrations. The contributions of this work are three-fold. First, we introduce HowTo100M: a large-scale dataset of 136 million video clips sourced from 1.22M narrated instructional web videos depicting humans performing and describing over 23k different visual tasks. Our data collection procedure is fast, scalable and does not require any additional manual annotation. Second, we demonstrate that a text-video embedding trained on this data leads to state-of-the-art results for text-to-video retrieval and action localization on instructional video datasets such as YouCook2 or CrossTask. Finally, we show that this embedding transfers well to other domains: fine-tuning on generic Youtube videos (MSR-VTT dataset) and movies (LSMDC dataset) outperforms models trained on these datasets alone. Our dataset, code and models are publicly available.
@inproceedings{miech2019howto100m, author = {Miech, Antoine and Zhukov, Dimitri and Alayrac, Jean-Baptiste and Tapaswi, Makarand and Laptev, Ivan and Sivic, Josef}, title = {{HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips}}, year = {2019}, booktitle = {International Conference on Computer Vision (ICCV)}, month = oct, doi = {10.1109/ICCV.2019.00272} } - [C21]
 Self-Supervised Learning of Face Representations for Video Face ClusteringIn IEEE International Conference on Automatic Face and Gesture Recognition (FG), May 2019🏆 Best Paper Award
Self-Supervised Learning of Face Representations for Video Face ClusteringIn IEEE International Conference on Automatic Face and Gesture Recognition (FG), May 2019🏆 Best Paper AwardAnalyzing the story behind TV series and movies often requires understanding who the characters are and what they are doing. With improving deep face models, this may seem like a solved problem. However, as face detectors get better, clustering/identification needs to be revisited to address increasing diversity in facial appearance. In this paper, we address video face clustering using unsupervised methods. Our emphasis is on distilling the essential information, identity, from the representations obtained using deep pre-trained face networks. We propose a self-supervised Siamese network that can be trained without the need for video/track based supervision, and thus can also be applied to image collections. We evaluate our proposed method on three video face clustering datasets. The experiments show that our methods outperform current state-of-the-art methods on all datasets. Video face clustering is lacking a common benchmark as current works are often evaluated with different metrics and/or different sets of face tracks. Our datasets and code will be made available for enabling fair comparisons in the future.
@inproceedings{sharma2019facecluster, author = {Sharma, Vivek and Tapaswi, Makarand and Sarfraz, Saquib and Stiefelhagen, Rainer}, title = {{Self-Supervised Learning of Face Representations for Video Face Clustering}}, year = {2019}, booktitle = {IEEE International Conference on Automatic Face and Gesture Recognition (FG)}, month = may, doi = {10.1109/FG.2019.8756609} } - [C20]
 Visual Reasoning by Progressive Module NetworksSeung Wook Kim, Makarand Tapaswi, and Sanja FidlerIn International Conference on Learning Representations (ICLR), May 2019
Visual Reasoning by Progressive Module NetworksSeung Wook Kim, Makarand Tapaswi, and Sanja FidlerIn International Conference on Learning Representations (ICLR), May 2019Humans learn to solve tasks of increasing complexity by building on top of previously acquired knowledge. Typically, there exists a natural progression in the tasks that we learn – most do not require completely independent solutions, but can be broken down into simpler subtasks. We propose to represent a solver for each task as a neural module that calls existing modules (solvers for simpler tasks) in a functional program-like manner. Lower modules are a black box to the calling module, and communicate only via a query and an output. Thus, a module for a new task learns to query existing modules and composes their outputs in order to produce its own output. Our model effectively combines previous skill-sets, does not suffer from forgetting, and is fully differentiable. We test our model in learning a set of visual reasoning tasks, and demonstrate improved performances in all tasks by learning progressively. By evaluating the reasoning process using human judges, we show that our model is more interpretable than an attention-based baseline.
@inproceedings{kim2019pmn, author = {Kim, Seung Wook and Tapaswi, Makarand and Fidler, Sanja}, title = {{Visual Reasoning by Progressive Module Networks}}, year = {2019}, booktitle = {International Conference on Learning Representations (ICLR)}, month = may } - [P1]
 The Shmoop Corpus: A Dataset of Stories with Loosely Aligned SummariesAtef Chaudhury, Makarand Tapaswi, Seung Wook Kim, and Sanja FidlerarXiv:1912.13082, Dec 2019
The Shmoop Corpus: A Dataset of Stories with Loosely Aligned SummariesAtef Chaudhury, Makarand Tapaswi, Seung Wook Kim, and Sanja FidlerarXiv:1912.13082, Dec 2019Understanding stories is a challenging reading comprehension problem for machines as it requires reading a large volume of text and following long-range dependencies. In this paper, we introduce the Shmoop Corpus: a dataset of 231 stories that are paired with detailed multi-paragraph summaries for each individual chapter (7,234 chapters), where the summary is chronologically aligned with respect to the story chapter. From the corpus, we construct a set of common NLP tasks, including Cloze-form question answering and a simplified form of abstractive summarization, as benchmarks for reading comprehension on stories. We then show that the chronological alignment provides a strong supervisory signal that learning-based methods can exploit leading to significant improvements on these tasks. We believe that the unique structure of this corpus provides an important foothold towards making machine story comprehension more approachable.
@article{chaudhury2019shmoop, author = {Chaudhury, Atef and Tapaswi, Makarand and Kim, Seung Wook and Fidler, Sanja}, title = {{The Shmoop Corpus: A Dataset of Stories with Loosely Aligned Summaries}}, year = {2019}, month = dec, journal = {arXiv:1912.13082} } - [W7]
 Deep Multimodal Feature Encoding for Video OrderingVivek Sharma, Makarand Tapaswi, and Rainer StiefelhagenIn ICCV Workshop on Large Scale Holistic Video Understanding, Dec 2019
Deep Multimodal Feature Encoding for Video OrderingVivek Sharma, Makarand Tapaswi, and Rainer StiefelhagenIn ICCV Workshop on Large Scale Holistic Video Understanding, Dec 2019True understanding of videos comes from a joint analysis of all its modalities: the video frames, the audio track, and any accompanying text such as closed captions. We present a way to learn a compact multimodal feature representation that encodes all these modalities. Our model parameters are learned through a proxy task of inferring the temporal ordering of a set of unordered videos in a timeline. To this end, we create a new multimodal dataset for temporal ordering that consists of approximately 30K scenes (2-6 clips per scene) based on the "Large Scale Movie Description Challenge". We analyze and evaluate the individual and joint modalities on three challenging tasks: (i) inferring the temporal ordering of a set of videos; and (ii) action recognition. We demonstrate empirically that multimodal representations are indeed complementary, and can play a key role in improving the performance of many applications.
@inproceedings{sharma2019tcbp, author = {Sharma, Vivek and Tapaswi, Makarand and Stiefelhagen, Rainer}, title = {{Deep Multimodal Feature Encoding for Video Ordering}}, year = {2019}, booktitle = {ICCV Workshop on Large Scale Holistic Video Understanding} }






2018
- [C19]
 MovieGraphs: Towards Understanding Human-Centric Situations from VideosIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2018
MovieGraphs: Towards Understanding Human-Centric Situations from VideosIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2018There is growing interest in artificial intelligence to build socially intelligent robots. This requires machines to have the ability to read people’s emotions, motivations, and other factors that affect behavior. Towards this goal, we introduce a novel dataset called MovieGraphs which provides detailed, graph-based annotations of social situations depicted in movie clips. Each graph consists of several types of nodes, to capture who is present in the clip, their emotional and physical attributes, their relationships (i.e., parent/child), and the interactions between them. Most interactions are associated with topics that provide additional details, and reasons that give motivations for actions. In addition, most interactions and many attributes are grounded in the video with time stamps. We provide a thorough analysis of our dataset, showing interesting common-sense correlations between different social aspects of scenes, as well as across scenes over time. We propose a method for querying videos and text with graphs, and show that: 1) our graphs contain rich and sufficient information to summarize and localize each scene; and 2) subgraphs allow us to describe situations at an abstract level and retrieve multiple semantically relevant situations. We also propose methods for interaction understanding via ordering, and reason understanding. MovieGraphs is the first benchmark to focus on inferred properties of human-centric situations, and opens up an exciting avenue towards socially-intelligent AI agents.
@inproceedings{vicol2018moviegraphs, author = {Vicol, Paul and Tapaswi, Makarand and Castrejon, Lluis and Fidler, Sanja}, title = {{MovieGraphs: Towards Understanding Human-Centric Situations from Videos}}, year = {2018}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR.2018.00895} } - [C18]
 Now You Shake Me: Towards Automatic 4D CinemaYuhao Zhou, Makarand Tapaswi, and Sanja FidlerIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2018
Now You Shake Me: Towards Automatic 4D CinemaYuhao Zhou, Makarand Tapaswi, and Sanja FidlerIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2018We are interested in enabling automatic 4D cinema by parsing physical and special effects from untrimmed movies. These include effects such as physical interactions, water splashing, light, and shaking, and are grounded to either a character in the scene or the camera. We collect a new dataset referred to as the Movie4D dataset which annotates over 9K effects in 63 movies. We propose a Conditional Random Field model atop a neural network that brings together visual and audio information, as well as semantics in the form of person tracks. Our model further exploits correlations of effects between different characters in the clip as well as across movie threads. We propose effect detection and classification as two tasks, and present results along with ablation studies on our dataset, paving the way towards 4D cinema in everyone’s homes.
@inproceedings{zhou2018movie4d, author = {Zhou, Yuhao and Tapaswi, Makarand and Fidler, Sanja}, title = {{Now You Shake Me: Towards Automatic 4D Cinema}}, year = {2018}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR.2018.00775} }


2017
- [C17]
 Situation Recognition with Graph Neural NetworksIn International Conference on Computer Vision (ICCV), Oct 2017
Situation Recognition with Graph Neural NetworksIn International Conference on Computer Vision (ICCV), Oct 2017We address the problem of recognizing situations in images. Given an image, the task is to predict the most salient verb (action), and fill its semantic roles such as who is performing the action, what is the source and target of the action, etc. Different verbs have different roles (e.g. attacking has weapon), and each role can take on many possible values (nouns). We propose a model based on Graph Neural Networks that allows us to efficiently capture joint dependencies between roles using neural networks defined on a graph. Experiments with different graph connectivities show that our approach that propagates information between roles significantly outperforms existing work, as well as multiple baselines. We obtain roughly 3-5% improvement over previous work in predicting the full situation. We also provide a thorough qualitative analysis of our model and influence of different roles in the verbs.
@inproceedings{li2017situggnn, author = {Li, Ruiyu and Tapaswi, Makarand and Liao, Renjie and Jia, Jiaya and Urtasun, Raquel and Fidler, Sanja}, title = {{Situation Recognition with Graph Neural Networks}}, year = {2017}, booktitle = {International Conference on Computer Vision (ICCV)}, month = oct, doi = {10.1109/ICCV.2017.448} }

2016
- [C16]
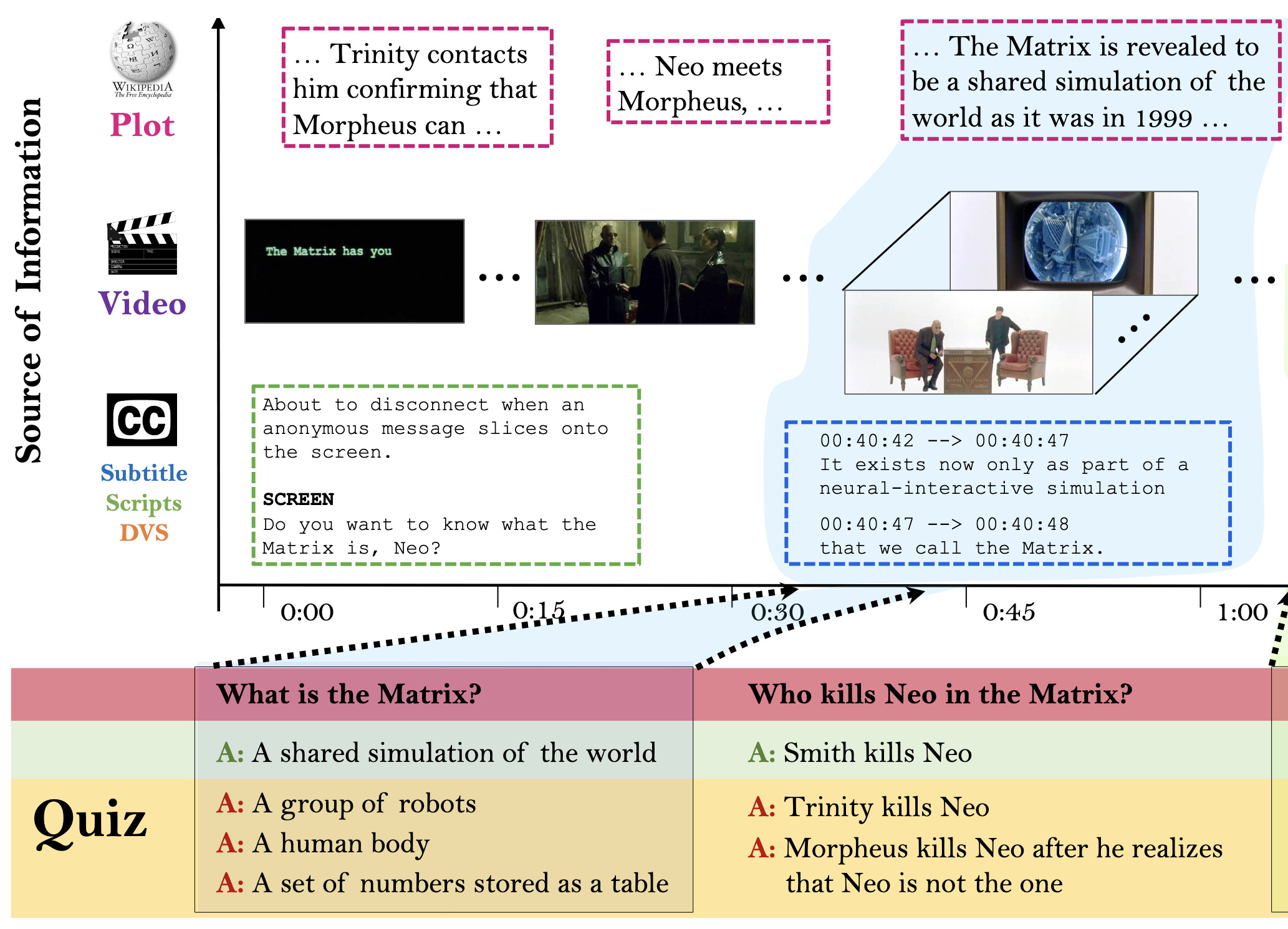 MovieQA: Understanding Stories in Movies through Question-AnsweringMakarand Tapaswi, Yukun Zhu, Rainer Stiefelhagen, Antonio Torralba, Raquel Urtasun, and Sanja FidlerIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2016
MovieQA: Understanding Stories in Movies through Question-AnsweringMakarand Tapaswi, Yukun Zhu, Rainer Stiefelhagen, Antonio Torralba, Raquel Urtasun, and Sanja FidlerIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2016We introduce the MovieQA dataset which aims to evaluate automatic story comprehension from both video and text. The dataset consists of 14,944 questions about 408 movies with high semantic diversity. The questions range from simpler “Who” did “What” to “Whom”, to “Why” and “How” certain events occurred. Each question comes with a set of five possible answers; a correct one and four deceiving answers provided by human annotators. Our dataset is unique in that it contains multiple sources of information – video clips, plots, subtitles, scripts, and DVS. We analyze our data through various statistics and methods. We further extend existing QA techniques to show that question-answering with such open-ended semantics is hard. We make this data set public along with an evaluation benchmark to encourage inspiring work in this challenging domain.
@inproceedings{tapaswi2016movieqa, author = {Tapaswi, Makarand and Zhu, Yukun and Stiefelhagen, Rainer and Torralba, Antonio and Urtasun, Raquel and Fidler, Sanja}, title = {{MovieQA: Understanding Stories in Movies through Question-Answering}}, year = {2016}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR.2016.501} } - [C15]
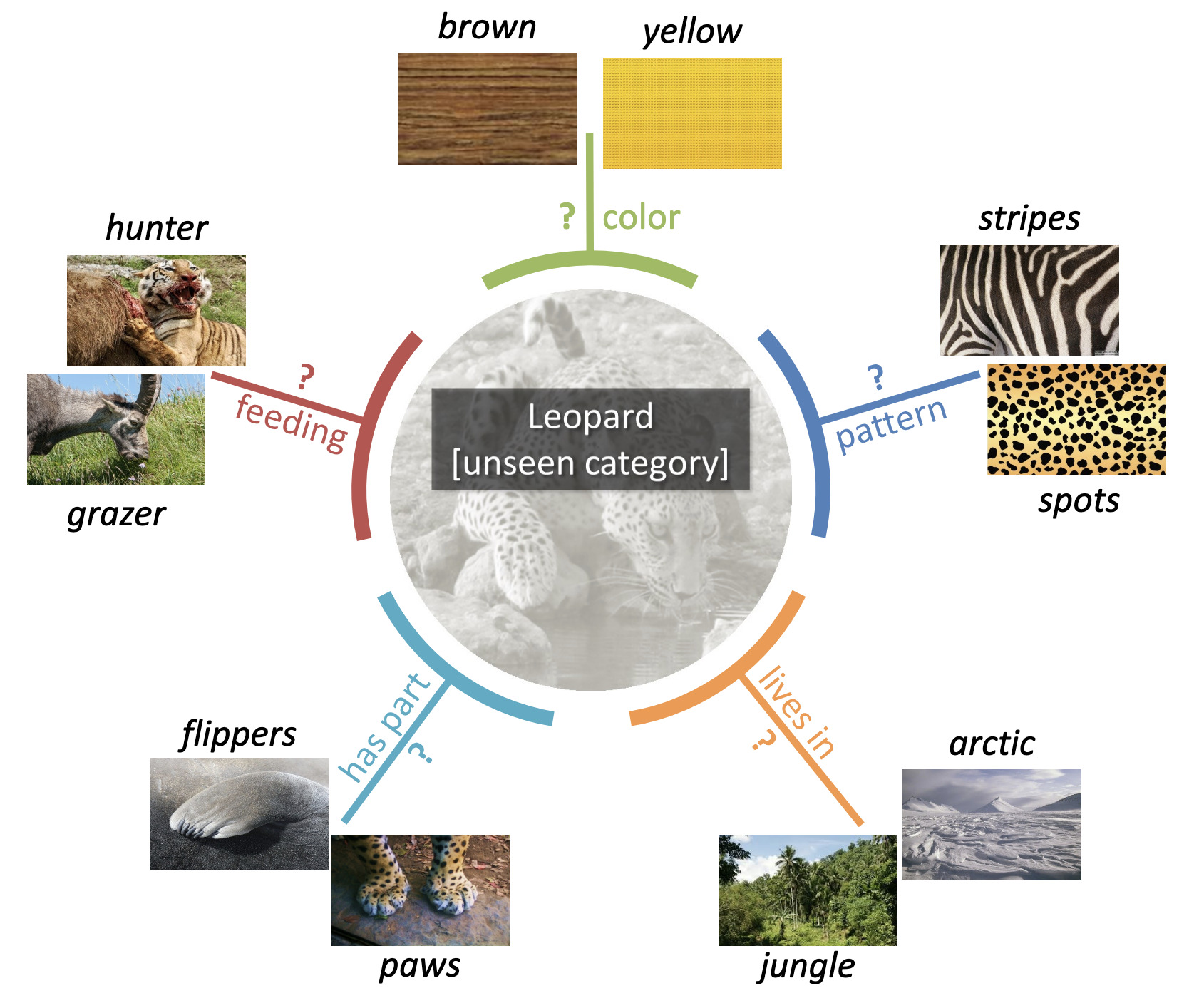 Recovering the Missing Link: Predicting Class-Attribute Associations for Unsupervised Zero-Shot LearningZiad Al-Halah, Makarand Tapaswi, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2016
Recovering the Missing Link: Predicting Class-Attribute Associations for Unsupervised Zero-Shot LearningZiad Al-Halah, Makarand Tapaswi, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2016Collecting training images for all visual categories is not only expensive but also impractical. Zero-shot learning (ZSL), especially using attributes, offers a pragmatic solution to this problem. However, at test time most attribute-based methods require a full description of attribute associations for each unseen class. Providing these associations is time consuming and often requires domain specific knowledge. In this work, we aim to carry out attribute- based zero-shot classification in an unsupervised manner. We propose an approach to learn relations that couples class embeddings with their corresponding attributes. Given only the name of an unseen class, the learned relationship model is used to automatically predict the class-attribute associations. Furthermore, our model facilitates transferring attributes across data sets without additional effort. Integrating knowledge from multiple sources results in a significant additional improvement in performance. We evaluate on two public data sets: Animals with Attributes and aPascal/aYahoo. Our approach outperforms state-of-the-art methods in both predicting class-attribute associations and unsupervised ZSL by a large margin.
@inproceedings{alhalah2016clsattrassoc, author = {Al-Halah, Ziad and Tapaswi, Makarand and Stiefelhagen, Rainer}, title = {{Recovering the Missing Link: Predicting Class-Attribute Associations for Unsupervised Zero-Shot Learning}}, year = {2016}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR.2016.643} } - [C14]
 Naming TV Characters by Watching and Analyzing DialogsIn Winter Conference on Applications of Computer Vision (WACV), Mar 2016
Naming TV Characters by Watching and Analyzing DialogsIn Winter Conference on Applications of Computer Vision (WACV), Mar 2016Person identification in TV series has been a popular research topic over the last decade. In this area, most approaches either use manually annotated data or extract character supervision from a combination of subtitles and transcripts. However, both approaches have key drawbacks that hinder application of these methods at a large scale – manual annotation is expensive and transcripts are often hard to obtain. We investigate the topic of automatically labeling all character appearances in TV series using information obtained solely from subtitles. This task is extremely difficult as the dialogs between characters provide very sparse and weakly supervised data. We address these challenges by exploiting recent advances in face descriptors and Multiple Instance Learning methods. We propose methods to create MIL bags and evaluate and discuss several MIL techniques. The best combination achieves an average precision over 80% on three diverse TV series. We demonstrate that only using subtitles provides good results on identifying characters in TV series and wish to encourage the community towards this problem.
@inproceedings{haurilet2016srtid, author = {Haurilet, Monica-Laura and Tapaswi, Makarand and Al-Halah, Ziad and Stiefelhagen, Rainer}, title = {{Naming TV Characters by Watching and Analyzing Dialogs}}, year = {2016}, booktitle = {Winter Conference on Applications of Computer Vision (WACV)}, month = mar, doi = {10.1109/WACV.2016.7477560} } - [W6]
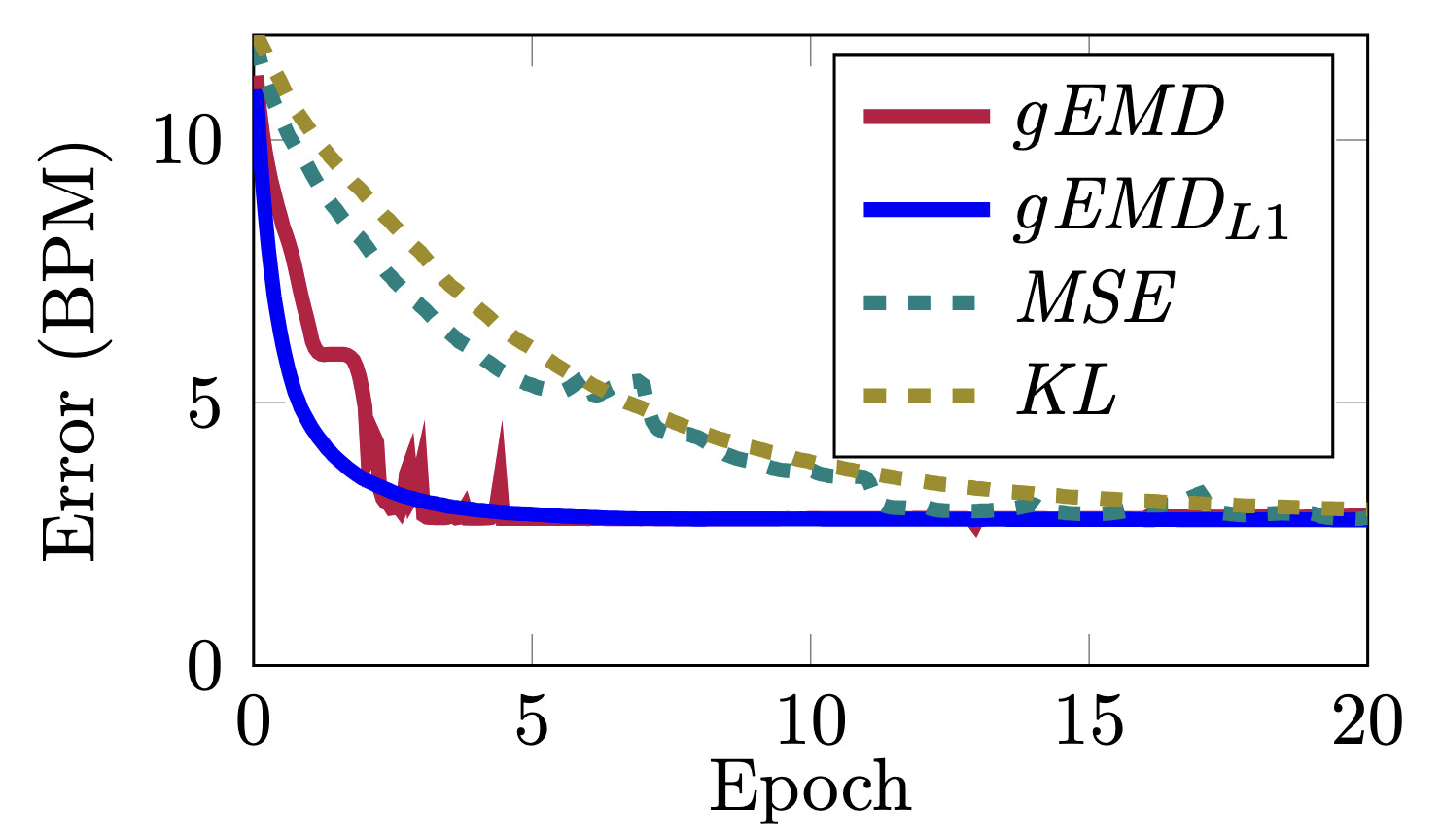 A Closed-form Gradient for the 1D Earth Mover’s Distance for Spectral Deep Learning on Biological DataManuel Martinez, Makarand Tapaswi, and Rainer StiefelhagenIn ICML Workshop on Computational Biology (CompBio-ICML16), Jun 2016
A Closed-form Gradient for the 1D Earth Mover’s Distance for Spectral Deep Learning on Biological DataManuel Martinez, Makarand Tapaswi, and Rainer StiefelhagenIn ICML Workshop on Computational Biology (CompBio-ICML16), Jun 2016@inproceedings{martinez2016icmlcompbiow, author = {Martinez, Manuel and Tapaswi, Makarand and Stiefelhagen, Rainer}, title = {{A Closed-form Gradient for the 1D Earth Mover's Distance for Spectral Deep Learning on Biological Data}}, year = {2016}, booktitle = {ICML Workshop on Computational Biology (CompBio-ICML16)}, month = jun }




2015
- [C13]
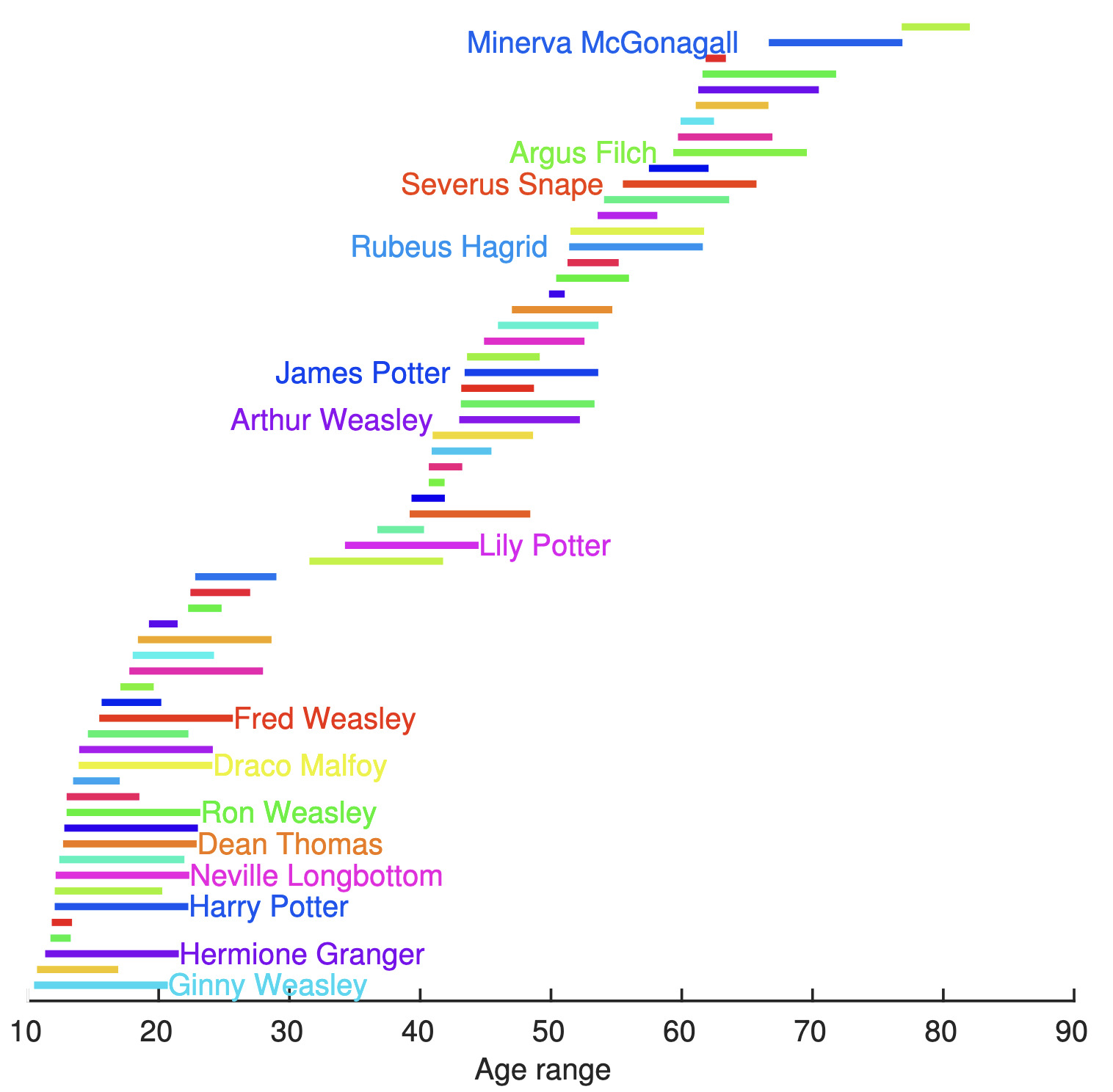 Accio: A Data Set for Face Track Retrieval in Movies Across AgeIn International Conference on Multimedia Retrieval (ICMR), Jun 2015
Accio: A Data Set for Face Track Retrieval in Movies Across AgeIn International Conference on Multimedia Retrieval (ICMR), Jun 2015Video face recognition is a very popular task and has come a long way. The primary challenges such as illumination, resolution and pose are well studied through multiple data sets. However there are no video-based data sets dedicated to study the effects of aging on facial appearance. We present a challenging face track data set, Harry Potter Movies Aging Data set (Accio), to study and develop age invariant face recognition methods for videos. Our data set not only has strong challenges of pose, illumination and distractors, but also spans a period of ten years providing substantial variation in facial appearance. We propose two primary tasks: within and across movie face track retrieval; and two protocols which differ in their freedom to use external data. We present baseline results for the retrieval performance using a state-of-the-art face track descriptor. Our experiments show clear trends of reduction in performance as the age gap between the query and database increases. We will make the data set publicly available for further exploration in age-invariant video face recognition.
@inproceedings{ghaleb2015accio, author = {Ghaleb, Esam and Tapaswi, Makarand and Al-Halah, Ziad and Ekenel, Hazım Kemal and Stiefelhagen, Rainer}, title = {{Accio: A Data Set for Face Track Retrieval in Movies Across Age}}, year = {2015}, booktitle = {International Conference on Multimedia Retrieval (ICMR)}, month = jun, doi = {10.1145/2671188.2749296} } - [C12]
 Book2Movie: Aligning Video scenes with Book chaptersMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2015
Book2Movie: Aligning Video scenes with Book chaptersMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2015Film adaptations of novels often visually display in a few shots what is described in many pages of the source novel. In this paper we present a new problem: to align book chapters with video scenes. Such an alignment facilitates finding differences between the adaptation and the original source, and also acts as a basis for deriving rich descriptions from the novel for the video clips. We propose an efficient method to compute an alignment between book chapters and video scenes using matching dialogs and character identities as cues. A major consideration is to allow the alignment to be non-sequential. Our suggested shortest path based approach deals with the non-sequential alignments and can be used to determine whether a video scene was part of the original book. We create a new data set involving two popular novel-to-film adaptations with widely varying properties and compare our method against other text-to-video alignment baselines. Using the alignment, we present a qualitative analysis of describing the video through rich narratives obtained from the novel.
@inproceedings{tapaswi2015book2movie, author = {Tapaswi, Makarand and Baeuml, Martin and Stiefelhagen, Rainer}, title = {{Book2Movie: Aligning Video scenes with Book chapters}}, year = {2015}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR.2015.7298792} } - [J1]
 Aligning Plot Synopses to Videos for Story-based RetrievalMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenInternational Journal of Multimedia Information Retrieval (IJMIR), Jun 2015
Aligning Plot Synopses to Videos for Story-based RetrievalMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenInternational Journal of Multimedia Information Retrieval (IJMIR), Jun 2015We propose a method to facilitate search through the storyline of TV series episodes. To this end, we use human written, crowdsourced descriptions – plot synopses – of the story conveyed in the video. We obtain such synopses from websites such as Wikipedia and propose various methods to align each sentence of the plot to shots in the video. Thus, the semantic story-based video retrieval problem is transformed into a much simpler text-based search. Finally, we return the set of shots aligned to the sentences as the video snippet corresponding to the query. The alignment is performed by first computing a similarity score between every shot and sentence through cues such as character identities and keyword matches between plot synopses and subtitles. We then formulate the alignment as an optimization problem and solve it efficiently using dynamic programming. We evaluate our methods on the fifth season of a TV series Buffy the Vampire Slayer and show encouraging results for both the alignment and the retrieval of story events.
@article{tapaswi2015plotalign, author = {Tapaswi, Makarand and Baeuml, Martin and Stiefelhagen, Rainer}, title = {{Aligning Plot Synopses to Videos for Story-based Retrieval}}, year = {2015}, journal = {International Journal of Multimedia Information Retrieval (IJMIR)}, volume = {4}, pages = {3-16}, doi = {10.1007/s13735-014-0065-9} } - [C11]
 Improved Weak Labels using Contextual Cues for Person Identification in VideosMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn International Conference on Automatic Face and Gesture Recognition (FG), May 2015
Improved Weak Labels using Contextual Cues for Person Identification in VideosMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn International Conference on Automatic Face and Gesture Recognition (FG), May 2015Fully automatic person identification in TV series has been achieved by obtaining weak labels from subtitles and transcripts [Everingham 2011]. In this paper, we revisit the problem of matching subtitles with face tracks to obtain more assignments and more accurate weak labels. We perform a detailed analysis of the state-of-the-art showing the types of errors during the assignment and providing insights into their cause. We then propose to model the problem of assigning names to face tracks as a joint optimization problem. Using negative constraints between co-occurring pairs of tracks and positive constraints from track threads, we are able to significantly improve the speaker assignment performance. This directly influences the identification performance on all face tracks. We also propose a new feature to determine whether a tracked face is speaking and show further improvements in performance while being computationally more efficient.
@inproceedings{tapaswi2015speakingface, author = {Tapaswi, Makarand and Baeuml, Martin and Stiefelhagen, Rainer}, title = {{Improved Weak Labels using Contextual Cues for Person Identification in Videos}}, year = {2015}, booktitle = {International Conference on Automatic Face and Gesture Recognition (FG)}, month = may, doi = {10.1109/FG.2015.7163083} } - [W5]KIT at MediaEval 2015 – Evaluating Visual Cues for Affective Impact of Movies TaskMarin Vlastelica Pogančić, Sergey Hayrapetyan, Makarand Tapaswi, and Rainer StiefelhagenIn MediaEval2015 Multimedia Benchmark Workshop (MediaEval2015), Sep 2015
We present the approach and results of our system on the MediaEval Affective Impact of Movies Task. The challenge involves two primary tasks: affect classification and violence detection. We test the performance of multiple visual features followed by linear SVM classifiers. Inspired by successes in different vision fields, we use (i) GIST features used in scene modeling, (ii) features extracted from a deep convolutional neural network trained on object recognition, and (iii) improved dense trajectory features encoded using Fisher vectors commonly used in action recognition.
@inproceedings{vlastelica2015mediaeval, author = {Pogančić, Marin Vlastelica and Hayrapetyan, Sergey and Tapaswi, Makarand and Stiefelhagen, Rainer}, title = {{KIT at MediaEval 2015 -- Evaluating Visual Cues for Affective Impact of Movies Task}}, year = {2015}, booktitle = {MediaEval2015 Multimedia Benchmark Workshop (MediaEval2015)}, month = sep }




2014
- [C10]
 Total Cluster: A person agnostic clustering method for broadcast videosMakarand Tapaswi, Omkar M. Parkhi, Esa Rahtu, Eric Sommerlade, Rainer Stiefelhagen, and Andrew ZissermanIn Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Dec 2014
Total Cluster: A person agnostic clustering method for broadcast videosMakarand Tapaswi, Omkar M. Parkhi, Esa Rahtu, Eric Sommerlade, Rainer Stiefelhagen, and Andrew ZissermanIn Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Dec 2014The goal of this paper is unsupervised face clustering in edited video material – where face tracks arising from different people are assigned to separate clusters, with one cluster for each person. In particular we explore the extent to which faces can be clustered automatically without making an error. This is a very challenging problem given the variation in pose, lighting and expressions that can occur, and the similarities between different people. The novelty we bring is three fold: first, we show that a form of weak supervision is available from the editing structure of the material – the shots, threads and scenes that are standard in edited video; second, we show that by first clustering within scenes the number of face tracks can be significantly reduced with almost no errors; third, we propose an extension of the clustering method to entire episodes using exemplar SVMs based on the negative training data automatically harvested from the editing structure. The method is demonstrated on multiple episodes from two very different TV series, Scrubs and Buffy. For both series it is shown that we move towards our goal, and also outperform a number of baselines from previous works.
@inproceedings{tapaswi2014tvcluster, author = {Tapaswi, Makarand and Parkhi, Omkar M. and Rahtu, Esa and Sommerlade, Eric and Stiefelhagen, Rainer and Zisserman, Andrew}, title = {{Total Cluster: A person agnostic clustering method for broadcast videos}}, year = {2014}, booktitle = {Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP)}, month = dec, doi = {10.1145/2683483.2683490} } - [C9]
 Cleaning up after a Face Tracker: False Positive RemovalIn International Conference on Image Processing (ICIP), Oct 2014
Cleaning up after a Face Tracker: False Positive RemovalIn International Conference on Image Processing (ICIP), Oct 2014Automatic person identification in TV series has gained popularity over the years. While most of the works rely on using face-based recognition, errors during tracking such as false positive face tracks are typically ignored. We propose a variety of methods to remove false positive face tracks and categorize the methods into confidence- and context-based. We evaluate our methods on a large TV series data set and show that up to 75% of the false positive face tracks are removed at the cost of 3.6% true positive tracks. We further show that the proposed method is general and applicable to other detectors or trackers.
@inproceedings{tapaswi2014fptrack, author = {Tapaswi, Makarand and Çörez, Cemal Çağrı and Baeuml, Martin and Ekenel, Hazım Kemal and Stiefelhagen, Rainer}, title = {{Cleaning up after a Face Tracker: False Positive Removal}}, year = {2014}, booktitle = {International Conference on Image Processing (ICIP)}, month = oct, doi = {10.1109/ICIP.2014.7025050} } - [C8]
 A Time Pooled Track Kernel for Person IdentificationMartin Baeuml, Makarand Tapaswi, and Rainer StiefelhagenIn Conference on Advanced Video and Signal-based Surveillance (AVSS), Aug 2014
A Time Pooled Track Kernel for Person IdentificationMartin Baeuml, Makarand Tapaswi, and Rainer StiefelhagenIn Conference on Advanced Video and Signal-based Surveillance (AVSS), Aug 2014We present a novel method for comparing tracks by means of a time pooled track kernel. In contrast to spatial or feature-space pooling, the track kernel pools base kernel results within tracks over time. It includes as special cases frame-wise classification on the one hand and the normalized sum kernel on the other hand. We also investigate non-Mercer instantiations of the track kernel and obtain good results despite its Gram matrices not being positive semidefinite. Second, the track kernel matrices in general require less memory than single frame kernels, allowing to process larger datasets without resorting to subsampling. Finally, the track kernel formulation allows for very fast testing compared to frame-wise classification which is important in settings where user feedback is obtained and quick iterations of re-training and re-testing are required. We apply our approach to the task of video-based person identification in large scale settings and obtain state-of-the art results.
@inproceedings{baeuml2014trackkernel, author = {Baeuml, Martin and Tapaswi, Makarand and Stiefelhagen, Rainer}, title = {{A Time Pooled Track Kernel for Person Identification}}, year = {2014}, booktitle = {Conference on Advanced Video and Signal-based Surveillance (AVSS)}, month = aug, doi = {10.1109/AVSS.2014.6918636} } - [C7]
 StoryGraphs: Visualizing Character Interactions as a TimelineMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2014
StoryGraphs: Visualizing Character Interactions as a TimelineMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2014We present a novel way to automatically summarize and represent the storyline of a TV episode by visualizing character interactions as a chart. We also propose a scene detection method that lends itself well to generate over-segmented scenes which is used to partition the video. The positioning of character lines in the chart is formulated as an optimization problem which trades between the aesthetics and functionality of the chart. Using automatic person identification, we present StoryGraphs for 3 diverse TV series encompassing a total of 22 episodes. We define quantitative criteria to evaluate StoryGraphs and also compare them against episode summaries to evaluate their ability to provide an overview of the episode.
@inproceedings{tapaswi2014storygraphs, author = {Tapaswi, Makarand and Baeuml, Martin and Stiefelhagen, Rainer}, title = {{StoryGraphs: Visualizing Character Interactions as a Timeline}}, year = {2014}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR.2014.111} } - [C6]
 Story-based Video Retrieval in TV series using Plot SynopsesMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn International Conference on Multimedia Retrieval (ICMR), Apr 2014
Story-based Video Retrieval in TV series using Plot SynopsesMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn International Conference on Multimedia Retrieval (ICMR), Apr 2014We present a novel approach to search for plots in the storyline of structured videos such as TV series. To this end, we propose to align natural language descriptions of the videos, such as plot synopses, with the corresponding shots in the video. Guided by subtitles and person identities the alignment problem is formulated as an optimization task over all possible assignments and solved efficiently using dynamic programming. We evaluate our approach on a novel dataset comprising of the complete season 5 of Buffy the Vampire Slayer, and show good alignment performance and the ability to retrieve plots in the storyline.
@inproceedings{tapaswi2014plotretrieval, author = {Tapaswi, Makarand and Baeuml, Martin and Stiefelhagen, Rainer}, title = {{Story-based Video Retrieval in TV series using Plot Synopses}}, year = {2014}, booktitle = {International Conference on Multimedia Retrieval (ICMR)}, month = apr, doi = {10.1145/2578726.2578727} }





2013
- [C5]
 Semi-supervised Learning with Constraints for Person Identification in Multimedia DataMartin Baeuml, Makarand Tapaswi, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2013
Semi-supervised Learning with Constraints for Person Identification in Multimedia DataMartin Baeuml, Makarand Tapaswi, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2013We address the problem of person identification in TV series. We propose a unified learning framework for multi-class classification which incorporates labeled and unlabeled data, and constraints between pairs of features in the training. We apply the framework to train multinomial logistic regression classifiers for multi-class face recognition. The method is completely automatic, as the labeled data is obtained by tagging speaking faces using subtitles and fan transcripts of the videos. We demonstrate our approach on six episodes each of two diverse TV series and achieve state-of-the-art performance.
@inproceedings{baeuml2013semisupid, author = {Baeuml, Martin and Tapaswi, Makarand and Stiefelhagen, Rainer}, title = {{Semi-supervised Learning with Constraints for Person Identification in Multimedia Data}}, year = {2013}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR.2013.462} } - [W4]
 QCompere @ Repere 2013Hervé Bredin, Johann Poignant, Guillaume Fortier, Makarand Tapaswi, Viet Bac Le, Anindya Roy, Claude Barras, Sophie Rosset, Achintya Sarkar, Hua Gao, Alexis Mignon, Jakob Verbeek, Laurent Besacier, Georges Quénot, Hazım Kemal Ekenel, and Rainer StiefelhagenIn Workshop on Speech, Language and Audio in Multimedia (SLAM), Aug 2013
QCompere @ Repere 2013Hervé Bredin, Johann Poignant, Guillaume Fortier, Makarand Tapaswi, Viet Bac Le, Anindya Roy, Claude Barras, Sophie Rosset, Achintya Sarkar, Hua Gao, Alexis Mignon, Jakob Verbeek, Laurent Besacier, Georges Quénot, Hazım Kemal Ekenel, and Rainer StiefelhagenIn Workshop on Speech, Language and Audio in Multimedia (SLAM), Aug 2013We describe QCompere consortium submissions to the REPERE 2013 evaluation campaign. The REPERE challenge aims at gathering four communities (face recognition, speaker identification, optical character recognition and named entity detection) towards the same goal: multimodal person recognition in TV broadcast. First, four mono-modal components are introduced (one for each foregoing community) constituting the elementary building blocks of our various submissions. Then, depending on the target modality (speaker or face recognition) and on the task (supervised or unsupervised recognition), four different fusion techniques are introduced: they can be summarized as propagation-, classifier-, rule- or graph-based approaches. Finally, their performance is evaluated on REPERE 2013 test set and their advantages and limitations are discussed.
@inproceedings{bredin2013repere, author = {Bredin, Hervé and Poignant, Johann and Fortier, Guillaume and Tapaswi, Makarand and Le, Viet Bac and Roy, Anindya and Barras, Claude and Rosset, Sophie and Sarkar, Achintya and Gao, Hua and Mignon, Alexis and Verbeek, Jakob and Besacier, Laurent and Quénot, Georges and Ekenel, Hazım Kemal and Stiefelhagen, Rainer}, title = {{QCompere @ Repere 2013}}, year = {2013}, booktitle = {Workshop on Speech, Language and Audio in Multimedia (SLAM)}, month = aug }


2012
- [C4]
 Contextual Constraints for Person Retrieval in Camera NetworksMartin Baeuml, Makarand Tapaswi, Arne Schumann, and Rainer StiefelhagenIn Conference on Advanced Video and Signal-based Surveillance (AVSS), Sep 2012
Contextual Constraints for Person Retrieval in Camera NetworksMartin Baeuml, Makarand Tapaswi, Arne Schumann, and Rainer StiefelhagenIn Conference on Advanced Video and Signal-based Surveillance (AVSS), Sep 2012We use contextual constraints for person retrieval in camera networks. We start by formulating a set of general positive and negative constraints on the identities of person tracks in camera networks, such as a person cannot appear twice in the same frame. We then show how these constraints can be used to improve person retrieval. First, we use the constraints to obtain training data in an unsupervised way to learn a general metric that is better suited to discriminate between different people than the Euclidean distance. Second, starting from an initial query track, we enhance the query-set using the constraints to obtain additional positive and negative samples for the query. Third, we formulate the person retrieval task as an energy minimization problem, integrate track scores and constraints in a common framework and jointly optimize the retrieval over all interconnected tracks. We evaluate our approach on the CAVIAR dataset and achieve 22% relative performance improvement in terms of mean average precision over standard retrieval where each track is treated independently.
@inproceedings{baeuml2012camnetwork, author = {Baeuml, Martin and Tapaswi, Makarand and Schumann, Arne and Stiefelhagen, Rainer}, title = {{Contextual Constraints for Person Retrieval in Camera Networks}}, year = {2012}, booktitle = {Conference on Advanced Video and Signal-based Surveillance (AVSS)}, month = sep, doi = {10.1109/AVSS.2012.28} } - [C3]
 “Knock! Knock! Who is it?” Probabilistic Person Identification in TV seriesMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2012
“Knock! Knock! Who is it?” Probabilistic Person Identification in TV seriesMakarand Tapaswi, Martin Baeuml, and Rainer StiefelhagenIn Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2012We describe a probabilistic method for identifying characters in TV series or movies. We aim at labeling every character appearance, and not only those where a face can be detected. Consequently, our basic unit of appearance is a person track (as opposed to a face track). We model each TV series episode as a Markov Random Field, integrating face recognition, clothing appearance, speaker recognition and contextual constraints in a probabilistic manner. The identification task is then formulated as an energy minimization problem. In order to identify tracks without faces, we learn clothing models by adapting available face recognition results. Within a scene, as indicated by prior analysis of the temporal structure of the TV series, clothing features are combined by agglomerative clustering. We evaluate our approach on the first 6 episodes of The Big Bang Theory and achieve an absolute improvement of 20% for person identification and 12% for face recognition.
@inproceedings{tapaswi2012personid, author = {Tapaswi, Makarand and Baeuml, Martin and Stiefelhagen, Rainer}, title = {{``Knock! Knock! Who is it?'' Probabilistic Person Identification in TV series}}, year = {2012}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, doi = {10.1109/CVPR.2012.6247986} } - [W3]
 Fusion of Speech, Faces and Text for Person Identification in TV BroadcastHervé Bredin, Johann Poignant, Makarand Tapaswi, Guillaume Fortier, Viet Bac Le, Thibault Napoleon, Hua Gao, Claude Barras, Sophie Rosset, Laurent Besacier, Jakob Verbeek, Georges Quénot, Frédéric Jurie, and Hazım Kemal EkenelIn Workshop on Information Fusion in Computer Vision for Concept Recognition (held with ECCV 2012) (IFCVCR), Oct 2012
Fusion of Speech, Faces and Text for Person Identification in TV BroadcastHervé Bredin, Johann Poignant, Makarand Tapaswi, Guillaume Fortier, Viet Bac Le, Thibault Napoleon, Hua Gao, Claude Barras, Sophie Rosset, Laurent Besacier, Jakob Verbeek, Georges Quénot, Frédéric Jurie, and Hazım Kemal EkenelIn Workshop on Information Fusion in Computer Vision for Concept Recognition (held with ECCV 2012) (IFCVCR), Oct 2012The Repere challenge is a project aiming at the evaluation of systems for supervised and unsupervised multimodal recognition of people in TV broadcast. In this paper, we describe, evaluate and discuss QCompere consortium submissions to the 2012 Repere evaluation campaign dry-run. Speaker identification (and face recognition) can be greatly improved when combined with name detection through video optical character recognition. Moreover, we show that unsupervised multimodal person recognition systems can achieve performance nearly as good as supervised monomodal ones (with several hundreds of identity models).
@inproceedings{bredin2012repere, author = {Bredin, Hervé and Poignant, Johann and Tapaswi, Makarand and Fortier, Guillaume and Le, Viet Bac and Napoleon, Thibault and Gao, Hua and Barras, Claude and Rosset, Sophie and Besacier, Laurent and Verbeek, Jakob and Quénot, Georges and Jurie, Frédéric and Ekenel, Hazım Kemal}, title = {{Fusion of Speech, Faces and Text for Person Identification in TV Broadcast}}, year = {2012}, booktitle = {Workshop on Information Fusion in Computer Vision for Concept Recognition (held with ECCV 2012) (IFCVCR)}, month = oct, doi = {10.1007/978-3-642-33885-4_39} } - [W2]
 KIT at MediaEval2012 - Content-based Genre Classification with Visual CuesTomas Semela, Makarand Tapaswi, Hazım Kemal Ekenel, and Rainer StiefelhagenIn MediaEval2012 Multimedia Benchmark Workshop (MediaEval2012), Oct 2012
KIT at MediaEval2012 - Content-based Genre Classification with Visual CuesTomas Semela, Makarand Tapaswi, Hazım Kemal Ekenel, and Rainer StiefelhagenIn MediaEval2012 Multimedia Benchmark Workshop (MediaEval2012), Oct 2012This paper presents the results of our content–based video genre classification system on the 2012 MediaEval Tagging Task. Our system utilizes several low–level visual cues to achieve this task. The purpose of this evaluation is to assess our content–based system’s performance on the large amount of blip.tv web–videos and high number of genres. The task and corpus are described in detail in [Schmeideke 2012].
@inproceedings{semela2012mediaeval, author = {Semela, Tomas and Tapaswi, Makarand and Ekenel, Hazım Kemal and Stiefelhagen, Rainer}, title = {{KIT at MediaEval2012 - Content-based Genre Classification with Visual Cues}}, year = {2012}, booktitle = {MediaEval2012 Multimedia Benchmark Workshop (MediaEval2012)}, month = oct }




2010
- [C2]
 Direct modeling of spoken passwords for text-dependent speaker recognition by compressed time-feature representationsAmitava Das, and Makarand TapaswiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Mar 2010
Direct modeling of spoken passwords for text-dependent speaker recognition by compressed time-feature representationsAmitava Das, and Makarand TapaswiIn International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Mar 2010Traditional Text-Dependent Speaker Recognition (TDSR) systems model the user-specific spoken passwords with frame-based features such as MFCC and use DTW or HMM type classifiers to handle the variable length of the feature vector sequence. In this paper, we explore a direct modeling of the entire spoken password by a fixed-dimension vector called Compressed Feature Dynamics or CFD. Instead of the usual frame-by-frame feature extraction, the entire password utterance is first modeled by a 2-D Featurogram or FGRAM, which efficiently captures speaker-identity-specific speech dynamics. CFDs are compressed and approximated version of the FGRAMs and their fixed dimension allows the use of simpler classifiers. Overall, the proposed FGRAM-CFD framework provides an efficient and direct model to capture the speaker-identity information well for a TDSR system. As demonstrated in trials on a 344-speaker database, compared to traditional MFCC-based TDSR systems, the FGRAM-CFD framework shows quite encouraging performance at significantly lower complexity.
@inproceedings{das2010speakerid, author = {Das, Amitava and Tapaswi, Makarand}, title = {{Direct modeling of spoken passwords for text-dependent speaker recognition by compressed time-feature representations}}, year = {2010}, booktitle = {International Conference on Acoustics, Speech, and Signal Processing (ICASSP)}, month = mar }

2008
- [C1]
 Audio-Visual Person Authentication with Multiple Visualized-Speech Features and Multiple Face ProfilesAmitava Das, Ohil K. Manyam, and Makarand TapaswiIn Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Dec 2008
Audio-Visual Person Authentication with Multiple Visualized-Speech Features and Multiple Face ProfilesAmitava Das, Ohil K. Manyam, and Makarand TapaswiIn Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Dec 2008We present an Audio-visual person authentication system which extracts several novel "Visualized Speech Features" (VSF) from the spoken-password and multiple face profiles using a simple user-interface and combine these features to deliver high performance and resilience against imposter attacks. The spoken password is converted to a string of images formed by several visualized speech features. A compressed form of these VSFs preserves speaker identity in a compact manner. Simulation results on an in-house 210-user AV-user-ID database collected with wide variations of users in real-life office environments demonstrate separable distributions of client and imposter scores (0% EER), while offering low storage and computational complexities compared to conventional AV user-recognition methods.
@inproceedings{das2008audiovisual, author = {Das, Amitava and Manyam, Ohil K. and Tapaswi, Makarand}, title = {{Audio-Visual Person Authentication with Multiple Visualized-Speech Features and Multiple Face Profiles}}, year = {2008}, booktitle = {Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP)}, month = dec, doi = {10.1109/ICVGIP.2008.106} } - [W1]Multilingual spoken-password based user authentication in emerging economies using cellular phone networksAmitava Das, Ohil K. Manyam, Makarand Tapaswi, and Veeresh TaranalliIn Workshop on Spoken Language Technology (SLT), Dec 2008
Mobile phones are playing an important role in changing the socio-economic landscapes of emerging economies like India. A proper voice-based user authentication will help in many new mobile based applications including mobile-commerce and banking. We present our exploration and evaluation of an experimental set-up for user authentication in remote Indian villages using mobile phones and user-selected multilingual spoken passwords. We also present an effective speaker recognition method using a set of novel features called Compressed Feature Dynamics (CFD) which capture the speaker-identity effectively from the speech dynamics contained in the spoken passwords. Early trials demonstrate the effectiveness of the proposed method in handling noisy cell-phone speech. Compared to conventional text-dependent speaker recognition methods, the proposed CFD method delivers competitive performance while significantly reducing storage and computational complexity – an advantage highly beneficial for cell-phone based deployment of such user authentication systems.
@inproceedings{das2008multilingual, author = {Das, Amitava and Manyam, Ohil K. and Tapaswi, Makarand and Taranalli, Veeresh}, title = {{Multilingual spoken-password based user authentication in emerging economies using cellular phone networks}}, year = {2008}, booktitle = {Workshop on Spoken Language Technology (SLT)}, month = dec, doi = {10.1109/SLT.2008.4777826} }

Disclaimer
This publication material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.